Der verständliche Leitfaden für Einsteiger
Architektur, Funktionsweise und Bedeutung
Vektor-Datenbanken einfach erklärt: Der verständliche Leitfaden für Einsteiger
Vektor-Datenbanken gehören zu den wichtigsten Bausteinen moderner KI-Systeme. Wer heute über Large Language Models, semantische Suche, RAG oder intelligente Chatbots spricht, kommt an diesem Thema kaum vorbei. Trotzdem wirkt der Begriff auf viele Menschen zunächst technisch und abstrakt. Genau deshalb lohnt es sich, das Thema von Grund auf zu verstehen.
Dieser Beitrag erklärt dir Schritt für Schritt, was Vektor-Datenbanken sind, wie sie funktionieren, wofür sie genutzt werden und warum sie für moderne KI-Anwendungen so wichtig geworden sind. Du brauchst dafür kein Vorwissen in Mathematik, Informatik oder Machine Learning. Der Text ist bewusst so aufgebaut, dass du von null starten kannst und am Ende ein solides Verständnis mitnimmst.
Wenn du später mit RAG-Systemen, Wissensdatenbanken, semantischer Suche oder KI-Assistenten arbeiten willst, ist dieses Wissen eine sehr gute Grundlage.
Was ist eine Vektor-Datenbank?
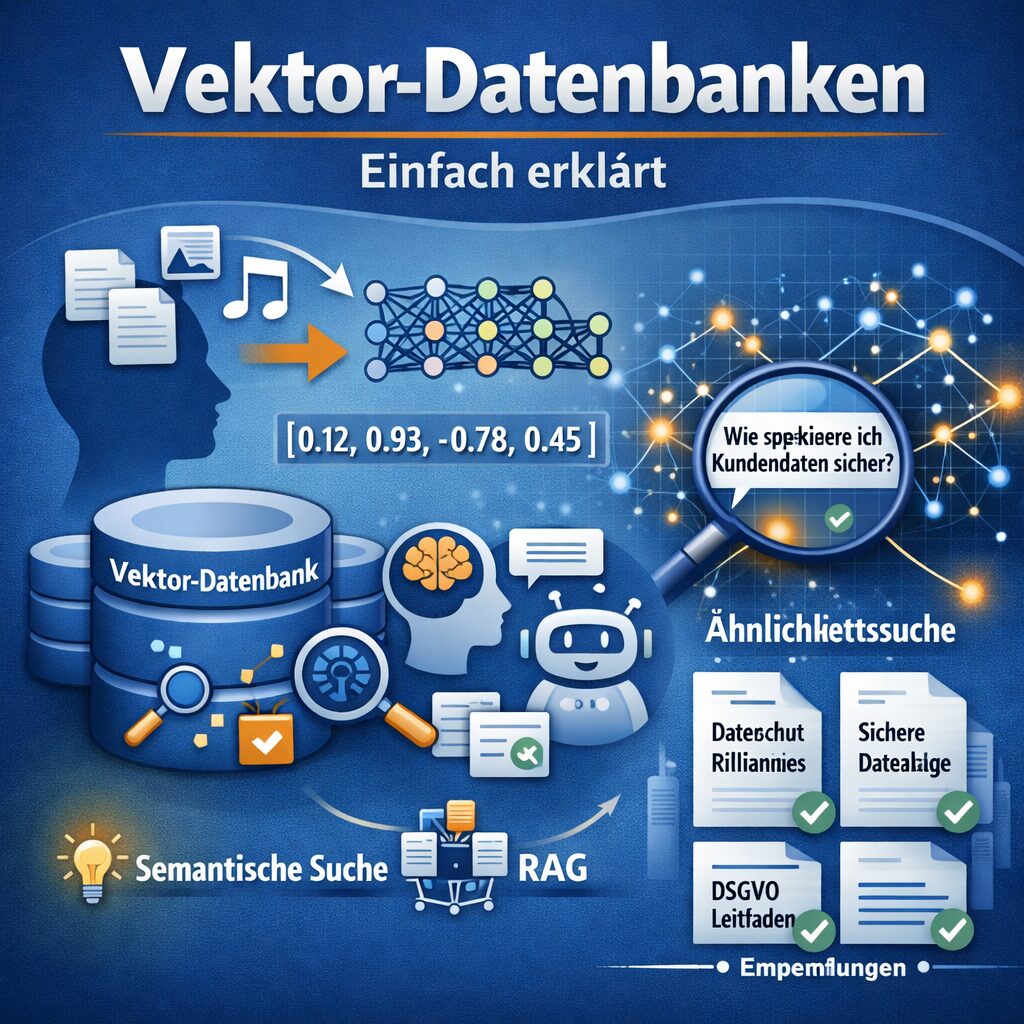
Eine Vektor-Datenbank ist eine spezielle Datenbank, die Informationen nicht nur als normalen Text, Zahlen oder Tabellen speichert, sondern als sogenannte Vektoren. Diese Vektoren sind mathematische Darstellungen von Inhalten.
Das klingt zunächst kompliziert, ist aber in der Praxis gut verständlich: Eine KI kann Texte, Bilder, Audiodateien oder andere Inhalte in Zahlenreihen umwandeln. Diese Zahlenreihen nennt man Vektoren oder Embeddings. In diesen Zahlen steckt vereinfacht gesagt die Bedeutung oder Ähnlichkeit eines Inhalts.
Eine Vektor-Datenbank speichert genau diese Embeddings und hilft dabei, ähnliche Inhalte sehr schnell wiederzufinden.
Statt also nur nach exakten Wörtern wie in einer klassischen Suche zu suchen, kann eine Vektor-Datenbank nach Bedeutung suchen. Das ist der große Unterschied.
Warum sind Vektor-Datenbanken für KI so wichtig?
Moderne KI-Systeme arbeiten oft mit Bedeutung, Kontext und Zusammenhängen. Ein Mensch fragt zum Beispiel:
„Welche Dokumente erklären, wie man Kundendaten DSGVO-konform speichert?“
Eine klassische Suche würde vielleicht nur nach den Wörtern „Kundendaten“, „DSGVO“ und „speichert“ suchen. Eine Vektor-Datenbank kann dagegen auch Inhalte finden, in denen zum Beispiel von „Datenschutz“, „personenbezogenen Daten“, „rechtskonformer Speicherung“ oder „Compliance“ die Rede ist, obwohl die exakten Wörter anders lauten.
Genau das macht Vektor-Datenbanken so wertvoll. Sie ermöglichen:
- semantische Suche
- intelligentere Chatbots
- Retrieval-Augmented Generation (RAG)
- bessere Empfehlungssysteme
- Ähnlichkeitssuche bei Texten, Bildern und Audio
- schnellere Wissensabfragen in großen Datenbeständen
Der Grundgedanke: Bedeutung in Zahlen umwandeln
Damit du Vektor-Datenbanken wirklich verstehst, musst du zuerst den Begriff Embedding verstehen.
Ein Embedding ist die numerische Darstellung eines Inhalts. Ein Satz wie:
„Die Katze schläft auf dem Sofa.“
wird von einem KI-Modell in eine Liste aus Zahlen umgewandelt. Diese Zahlen stehen nicht willkürlich da. Sie repräsentieren die Bedeutung des Satzes.
Ein anderer Satz wie:
„Ein Kater ruht auf der Couch.“
würde einen ähnlichen Vektor erhalten, weil die Bedeutung ähnlich ist. Ein Satz wie:
„Ein Flugzeug startet am Flughafen.“
würde weiter entfernt liegen.
Die Vektor-Datenbank speichert also nicht einfach nur Texte, sondern deren mathematische Bedeutungsform.
Was ist ein Vektor?
Ein Vektor ist in diesem Zusammenhang einfach eine geordnete Liste von Zahlen.
Ein ganz vereinfachtes Beispiel könnte so aussehen:
[0.14, -0.82, 0.33, 0.91, -0.07]
In echten KI-Systemen sind Vektoren oft viel größer. Sie können 384, 768, 1024 oder noch mehr Dimensionen haben. Jede dieser Zahlen trägt einen kleinen Teil zur Repräsentation der Bedeutung bei.
Du musst dir diese Zahlen nicht im Detail merken. Wichtiger ist dieses Verständnis:
Ein Vektor ist die Zahlenform von Bedeutung.
Was bedeutet semantische Suche?
Semantische Suche heißt, dass nicht nur nach exakten Begriffen gesucht wird, sondern nach dem inhaltlichen Sinn.
Klassische Suche
Eine klassische Datenbank oder Suchmaschine arbeitet oft mit Stichwörtern. Sie findet Ergebnisse dann besonders gut, wenn die Suchwörter exakt im Text vorkommen.
Semantische Suche
Eine semantische Suche versucht zu verstehen, was gemeint ist. Sie findet deshalb oft auch Inhalte, die ähnlich sind, obwohl andere Wörter verwendet wurden.
Beispiel
Suchanfrage:
„Wie lagere ich vertrauliche Kundendaten sicher?“
Ein semantisches System kann auch Dokumente finden wie:
- „Sichere Speicherung sensibler Kundeninformationen“
- „Best Practices für Datenschutz bei personenbezogenen Daten“
- „Datensicherheit im CRM-System“
Genau dafür braucht man Vektor-Datenbanken.
Wie funktioniert eine Vektor-Datenbank Schritt für Schritt?
Der Ablauf lässt sich in mehrere Schritte zerlegen.
1. Inhalte werden vorbereitet
Zuerst liegen Inhalte vor, zum Beispiel:
- Blogartikel
- PDFs
- Webseiten
- Produktbeschreibungen
- Support-Dokumente
- Chatverläufe
- Bilder oder Audiodateien
2. Inhalte werden in kleinere Abschnitte zerlegt
Gerade bei langen Dokumenten wird der Inhalt oft in kleinere Stücke aufgeteilt. Das nennt man Chunking.
Ein PDF mit 50 Seiten wird also nicht als ein riesiger Block gespeichert, sondern in viele kleinere Textabschnitte zerlegt. Das ist sinnvoll, weil die KI später gezielter passende Informationen finden kann.
3. Ein Embedding-Modell erzeugt Vektoren
Jeder Textabschnitt wird an ein Embedding-Modell geschickt. Dieses wandelt den Text in einen Vektor um.
Aus einem Absatz wird also eine Zahlenreihe.
4. Die Vektoren werden gespeichert
Die erzeugten Vektoren landen in der Vektor-Datenbank. Meist werden zusätzlich Metadaten gespeichert, zum Beispiel:
- Dokumentname
- Quelle
- Kategorie
- URL
- Datum
- Sprache
- Abschnittsnummer
5. Eine Nutzerfrage wird ebenfalls in einen Vektor umgewandelt
Wenn später jemand eine Frage stellt, wird auch diese Frage in einen Vektor umgewandelt.
6. Ähnliche Vektoren werden gesucht
Die Datenbank vergleicht nun den Vektor der Frage mit den gespeicherten Vektoren der Dokumente. Dabei sucht sie nach den ähnlichsten Einträgen.
7. Die relevantesten Inhalte werden zurückgegeben
Die ähnlichsten Textabschnitte werden an das KI-System oder den Nutzer zurückgegeben. Bei einem RAG-System werden diese Inhalte dann als Kontext an ein Sprachmodell übergeben.
Warum reicht eine normale Datenbank nicht aus?
Klassische relationale Datenbanken wie MySQL oder PostgreSQL sind hervorragend, wenn du strukturierte Daten speichern willst. Zum Beispiel:
- Kundennummer
- Name
- Preis
- Bestellstatus
Aber sie sind nicht darauf spezialisiert, Bedeutungsräume und Ähnlichkeiten in hochdimensionalen Vektoren effizient zu durchsuchen.
Eine normale Datenbank kann zwar vieles speichern, aber eine Vektor-Datenbank ist auf genau diesen Spezialfall optimiert:
schnelle Ähnlichkeitssuche in großen Mengen von Embeddings
Unterschied zwischen klassischer Datenbank und Vektor-Datenbank
| Merkmal | Klassische Datenbank | Vektor-Datenbank |
|---|---|---|
| Speichert vor allem | Strukturierte Daten | Embeddings und Metadaten |
| Typische Suche | Exakte Werte, Filter, Schlüsselwörter | Semantische Ähnlichkeit |
| Gut geeignet für | CRM, Shop, Buchhaltung, Nutzerkonten | KI-Suche, RAG, Empfehlungssysteme |
| Suchlogik | SQL, Filter, Relation | Similarity Search, Nearest Neighbor |
| Versteht Bedeutung | Nur sehr begrenzt | Ja, über Embeddings |
| Stärke | Struktur und Konsistenz | Kontext und semantische Nähe |
Was ist Similarity Search?
Similarity Search bedeutet Ähnlichkeitssuche. Die Datenbank sucht also nicht nach exakten Treffern, sondern nach Inhalten, die einem gesuchten Vektor möglichst ähnlich sind.
Dazu werden mathematische Verfahren genutzt, etwa:
- Cosine Similarity
- Euclidean Distance
- Dot Product
Du musst diese Begriffe nicht mathematisch ausrechnen können. Für das Grundverständnis reicht:
Je näher zwei Vektoren beieinanderliegen, desto ähnlicher sind die Inhalte.
Einfaches Bild im Kopf
Stell dir vor, jeder Text liegt als Punkt in einem riesigen Raum. Ähnliche Inhalte liegen nah beieinander. Sehr unterschiedliche Inhalte liegen weiter auseinander.
Wenn jetzt eine Suchanfrage kommt, wird auch sie zu einem Punkt in diesem Raum. Die Vektor-Datenbank schaut dann: Welche gespeicherten Punkte liegen am nächsten?
Diese „nächsten Nachbarn“ sind meist die relevantesten Ergebnisse.
Was sind Dimensionen bei Vektoren?
Die Dimensionen sind die einzelnen Zahlenpositionen in einem Vektor. Ein Vektor mit 384 Werten hat 384 Dimensionen. Ein Vektor mit 768 Werten hat 768 Dimensionen.
Mehr Dimensionen bedeuten nicht automatisch besser, aber häufig kann ein Modell dadurch feinere Bedeutungsunterschiede abbilden. Gleichzeitig steigen Speicherbedarf und Rechenaufwand.
Was sind Metadaten in einer Vektor-Datenbank?
Metadaten sind Zusatzinformationen, die mit einem Vektor gespeichert werden. Sie machen das System praktischer und steuerbarer.
Typische Metadaten sind:
- Titel des Dokuments
- Quell-URL
- Dateityp
- Sprache
- Thema
- Kunde oder Projekt
- Zeitpunkt der Erstellung
- Berechtigungsstufe
Diese Metadaten sind wichtig, weil man Suchergebnisse nicht nur nach Ähnlichkeit, sondern auch nach Regeln filtern möchte.
Beispiel
Du willst nur Inhalte finden, die:
- aus dem Bereich „Verträge“ stammen
- in deutscher Sprache sind
- nach Januar 2025 erstellt wurden
Dann kombiniert die Vektor-Datenbank semantische Suche mit Metadaten-Filtern.
Was ist Chunking und warum ist es so wichtig?
Chunking bedeutet, große Inhalte in kleine sinnvolle Abschnitte zu zerlegen. Das ist in KI-Systemen extrem wichtig.
Wenn du einen kompletten langen Artikel als einen einzigen Vektor speicherst, kann die Suche zu ungenau werden. Ein kleiner, präziser Abschnitt liefert meist bessere Ergebnisse.
Beispiel für sinnvolles Chunking
Ein Handbuch mit 100 Seiten wird aufgeteilt in:
- Einleitung
- Installation
- Login
- Benutzerrollen
- Datensicherung
- Fehlerbehebung
Oder sogar noch feiner in Absätze von 200 bis 500 Wörtern.
Warum Chunking entscheidend ist
| Ohne gutes Chunking | Mit gutem Chunking |
|---|---|
| Ergebnisse sind oft zu allgemein | Ergebnisse sind präziser |
| Wichtige Details gehen unter | Konkrete Antworten werden leichter gefunden |
| Kontext ist manchmal zu breit | Relevante Passagen werden gezielt geliefert |
| Schlechtere RAG-Antworten | Bessere KI-Antworten |
Was ist Retrieval-Augmented Generation (RAG)?
RAG ist ein Ansatz, bei dem ein Sprachmodell nicht nur auf seinem Trainingswissen basiert, sondern zusätzlich externe Inhalte aus einer Datenquelle erhält.
Genau hier kommen Vektor-Datenbanken ins Spiel.
So funktioniert RAG vereinfacht
- Ein Nutzer stellt eine Frage.
- Die Frage wird in einen Vektor umgewandelt.
- Die Vektor-Datenbank sucht passende Dokumentabschnitte.
- Diese Abschnitte werden an das Sprachmodell übergeben.
- Das Sprachmodell formuliert daraus eine Antwort.
Warum RAG so nützlich ist
Ein Sprachmodell allein kann veraltet sein oder halluzinieren. Mit RAG bekommt es konkrete, aktuelle oder firmenspezifische Informationen als Grundlage.
Das verbessert:
- Genauigkeit
- Nachvollziehbarkeit
- Aktualität
- Relevanz
Typische Einsatzbereiche von Vektor-Datenbanken
Vektor-Datenbanken werden in vielen modernen Anwendungen eingesetzt.
Wissenschatbots
Ein Unternehmen speichert interne Dokumente, Richtlinien und FAQs als Embeddings. Der Chatbot kann dann gezielt daraus antworten.
Dokumentensuche
Nutzer finden Inhalte nach Bedeutung statt nur nach Stichworten. Das ist besonders nützlich bei langen PDFs, Verträgen oder Wissensdatenbanken.
Produktempfehlungen
Ähnliche Produkte können anhand von Textbeschreibungen, Merkmalen oder Nutzerverhalten gefunden werden.
Bildersuche
Bilder lassen sich über Embeddings ebenfalls semantisch durchsuchen, etwa nach Motiv, Stil oder Ähnlichkeit.
Support-Systeme
Alte Supportfälle, Anleitungen und Lösungen können in ähnlichen Situationen schneller gefunden werden.
Personalisierte KI-Assistenten
Eigene Dokumente, Unternehmenswissen oder Fachwissen lassen sich in ein KI-System integrieren.
Beispiele aus der Praxis
| Anwendungsfall | Rolle der Vektor-Datenbank |
|---|---|
| Firmen-Chatbot | Findet passende interne Dokumente zu einer Frage |
| Online-Shop | Erkennt ähnliche Produkte und semantische Produktsuchen |
| Rechtsabteilung | Durchsucht Verträge und Klauseln nach Bedeutung |
| Medizinische Wissenssuche | Findet fachlich ähnliche Dokumente und Studien |
| E-Learning-Plattform | Liefert passende Lerninhalte zu einer Nutzerfrage |
| CRM-Analyse | Verknüpft ähnliche Kundenanfragen oder Supportfälle |
Wie entsteht ein Embedding?
Ein Embedding wird von einem speziellen KI-Modell erzeugt. Dieses Modell wurde darauf trainiert, Inhalte so in Zahlen umzuwandeln, dass ähnliche Bedeutungen auch mathematisch nah beieinanderliegen.
Beispiele für Inhalte, die in Embeddings umgewandelt werden können
- Texte
- Überschriften
- Fragen
- Produktbeschreibungen
- Bilder
- Audio
- Code
Bei deinem Wissensbereich auf einer KI-Webseite wird meist vor allem Text-Embedding relevant sein.
Warum Embeddings nicht einfach rohe Texte ersetzen
Ein Embedding ist keine Lesefassung für Menschen. Es ist eine Maschinenrepräsentation. Deshalb werden in guten Systemen meist beide Ebenen gespeichert:
- der Originaltext
- der zugehörige Vektor
So kann das System semantisch suchen, aber dem Nutzer am Ende wieder lesbare Inhalte anzeigen.
Wie schnell sind Vektor-Datenbanken?
Vektor-Datenbanken sind dafür gebaut, auch in sehr großen Datenmengen schnell ähnliche Inhalte zu finden. Das ist technisch anspruchsvoll, weil Millionen oder sogar Milliarden Vektoren durchsucht werden können.
Dafür werden spezielle Indexverfahren verwendet. Ein wichtiger Begriff ist dabei Approximate Nearest Neighbor Search, oft abgekürzt als ANN.
Was ist ANN?
ANN bedeutet, dass die Datenbank nicht immer die mathematisch absolut perfekten nächsten Nachbarn sucht, sondern sehr gute Näherungen, die viel schneller gefunden werden.
Das ist in der Praxis oft sinnvoll, weil:
- Geschwindigkeit sehr wichtig ist
- minimale Abweichungen meist keine Rolle spielen
- große Datenmengen sonst zu langsam wären
Warum Vektor-Datenbanken nicht „magisch“ sind
Vektor-Datenbanken sind sehr nützlich, aber sie lösen nicht automatisch jedes Problem. Die Qualität hängt stark davon ab:
- wie gut das Embedding-Modell ist
- wie sinnvoll das Chunking gemacht wurde
- welche Metadaten vorhanden sind
- wie sauber die Datenquelle ist
- wie gut die Suchstrategie eingestellt wurde
Wenn schlechte oder chaotische Daten eingespeist werden, hilft auch die beste Datenbank nur begrenzt.
Vorteile von Vektor-Datenbanken
| Vorteil | Erklärung |
|---|---|
| Semantische Suche | Inhalte werden nach Bedeutung statt nur nach Wörtern gefunden |
| Bessere KI-Antworten | Besonders nützlich für RAG und Wissenschatbots |
| Flexible Nutzung | Für Texte, Bilder, Audio und weitere Datenformen geeignet |
| Hohe Skalierbarkeit | Auch große Mengen an Embeddings können effizient durchsucht werden |
| Kontextstärker | Synonyme, ähnliche Formulierungen und verwandte Themen werden besser erkannt |
| Moderne KI-Basis | Zentral für viele aktuelle KI-Anwendungen |
Nachteile und Herausforderungen
| Nachteil | Erklärung |
|---|---|
| Höhere Komplexität | Aufbau und Betrieb sind anspruchsvoller als bei einfacher Volltextsuche |
| Abhängigkeit vom Embedding-Modell | Schlechte Embeddings führen zu schlechten Treffern |
| Speicher- und Rechenaufwand | Große Datenmengen können teuer werden |
| Qualitätsprobleme bei schlechtem Chunking | Unsaubere Aufteilung verschlechtert die Ergebnisse |
| Keine perfekte Logikmaschine | Ähnlichkeit ist nicht immer gleich fachlich korrekt |
| Zusätzliche Systemarchitektur nötig | Oft braucht man Pipeline, Indexierung, Monitoring und Filtersysteme |
Vektor-Datenbanken vs. Volltextsuche
Viele Einsteiger fragen sich, ob eine normale Volltextsuche nicht ausreicht. Die Antwort lautet: Das kommt auf den Anwendungsfall an.
Volltextsuche ist stark, wenn
- exakte Begriffe wichtig sind
- technische Begriffe exakt gefunden werden müssen
- strukturierte Stichwortsuche ausreicht
- einfache Systeme gebaut werden
Vektor-Suche ist stark, wenn
- ähnliche Bedeutung erkannt werden soll
- Nutzer ganz unterschiedlich formulieren
- Fragen in natürlicher Sprache gestellt werden
- RAG oder KI-Assistenten genutzt werden
In vielen professionellen Anwendungen werden heute beide Ansätze kombiniert. Das nennt man oft hybride Suche.
Was ist hybride Suche?
Hybride Suche kombiniert:
- klassische Keyword-Suche
- semantische Vektor-Suche
Das ist oft die beste Lösung. Denn manche Informationen findet man besser über exakte Begriffe, andere besser über Bedeutung.
Beispiel
Suche nach:
„Vertrag zur Untervermietung in Zypern“
Hier können exakte Begriffe wie „Untervermietung“ oder „Zypern“ wichtig sein. Gleichzeitig soll das System aber auch ähnliche Dokumente mit Formulierungen wie „Subletting“, „Mietüberlassung“ oder „temporäre Weitervermietung“ erkennen.
Hybride Suche verbindet beide Welten.
Welche Daten kann man in einer Vektor-Datenbank speichern?
Vektor-Datenbanken werden oft mit Text in Verbindung gebracht, aber sie sind breiter einsetzbar.
| Datentyp | Beispiel |
|---|---|
| Text | Artikel, E-Mails, Verträge, FAQs |
| Bilder | Produktfotos, medizinische Aufnahmen, Designbeispiele |
| Audio | Sprachaufnahmen, Transkripte, Musikmerkmale |
| Video | Szenenbeschreibungen, Bildfolgen, Metadaten |
| Code | Quellcode, Funktionsbeschreibungen, ähnliche Codeblöcke |
Für eine KI-Ratgeber-Webseite sind Texte der wichtigste Startpunkt. Später kannst du das Wissen aber auch mit PDFs, Leitfäden oder Datenblättern erweitern.
Wie sieht ein typischer Workflow aus?
Hier ist ein einfacher Praxisablauf für ein KI-Wissenssystem:
| Schritt | Was passiert? |
|---|---|
| 1 | Inhalte werden gesammelt, zum Beispiel Blogtexte oder PDFs |
| 2 | Inhalte werden bereinigt und in Abschnitte zerlegt |
| 3 | Für jeden Abschnitt wird ein Embedding erzeugt |
| 4 | Vektoren und Metadaten werden gespeichert |
| 5 | Nutzer stellt eine Frage |
| 6 | Die Frage wird ebenfalls embedded |
| 7 | Die Datenbank sucht ähnliche Abschnitte |
| 8 | Die relevantesten Treffer werden angezeigt oder an ein LLM übergeben |
Typische Begriffe, die du kennen solltest
Embedding
Numerische Darstellung eines Inhalts.
Similarity Search
Suche nach ähnlichen Vektoren.
Index
Struktur, die schnelle Suchvorgänge ermöglicht.
ANN
Approximate Nearest Neighbor, also schnelle Näherungssuche.
Chunking
Aufteilen langer Inhalte in kleinere Einheiten.
Metadata
Zusatzinformationen zu einem Eintrag.
RAG
Abruf externer Informationen zur Verbesserung von KI-Antworten.
Hybrid Search
Kombination aus Keyword-Suche und semantischer Suche.
Wann lohnt sich eine Vektor-Datenbank wirklich?
Nicht jede Webseite und nicht jedes Projekt braucht sofort eine Vektor-Datenbank. Sie lohnt sich besonders dann, wenn Inhalte in natürlicher Sprache intelligent durchsucht werden sollen.
Sinnvoll ist sie oft bei
- KI-Chatbots
- internen Wissenssystemen
- Support-Centern
- Dokumentensammlungen
- Recherchetools
- semantischen Suchfunktionen
- RAG-Projekten
Weniger sinnvoll ist sie oft bei
- sehr kleinen statischen Datensätzen
- rein strukturierten Tabellen
- einfachen Filterabfragen
- Projekten ohne semantische Suche
Typische Fehler beim Einsatz von Vektor-Datenbanken
Gerade Einsteiger machen oft ähnliche Fehler. Das ist normal.
1. Zu große Textblöcke speichern
Wenn Dokumente nicht sauber gechunkt werden, leidet die Suchqualität.
2. Schlechte oder irrelevante Daten importieren
Eine KI findet nur das, was du ihr gibst. Müll rein, Müll raus.
3. Nur auf Vektor-Suche setzen
In vielen Fällen ist eine hybride Suche deutlich besser.
4. Keine Metadaten speichern
Dann wird die Suche später unflexibel und schwer kontrollierbar.
5. Falsches Embedding-Modell nutzen
Nicht jedes Modell passt zu jeder Sprache, Domäne oder Datenart.
Vektor-Datenbanken für WordPress- und Content-Projekte
Wenn du eine KI-Ratgeber-Webseite betreibst, können Vektor-Datenbanken auf mehreren Ebenen interessant sein.
Mögliche Einsatzszenarien
- intelligente Artikelsuche
- KI-Chat mit den Inhalten deiner Website
- semantische FAQ-Suche
- automatisierte Wissensnavigation
- bessere Related-Content-Systeme
- Recherche-Assistent für Leser
Beispiel für deine Wissensseite
Du baust Bereiche auf wie:
- LLM
- RAG
- KI-Glossar
- Prompt Engineering
- Agenten
- Embeddings
- Fine-Tuning
- Automatisierung
Eine Vektor-Datenbank könnte später alle diese Inhalte semantisch verknüpfen. Ein Leser, der nach „Wie findet eine KI relevante Informationen in Dokumenten?“ sucht, könnte dann passende Inhalte aus mehreren Artikeln gleichzeitig finden.
Bekannte Vektor-Datenbanken und Lösungen
Es gibt verschiedene bekannte Systeme am Markt. Für einen Grundlagenartikel ist es wichtiger, die Konzepte zu verstehen als jedes Produkt im Detail. Trotzdem ist ein grober Überblick hilfreich.
| Lösungstyp | Beschreibung |
|---|---|
| Reine Vektor-Datenbanken | Speziell für Embeddings und Ähnlichkeitssuche entwickelt |
| Suchmaschinen mit Vektor-Funktionen | Klassische Suche plus semantische Komponenten |
| Klassische Datenbanken mit Vektor-Erweiterung | Bestehende Datenbanken werden um Vektor-Suche erweitert |
| Cloud-basierte KI-Speicherlösungen | Verwaltete Services für Embeddings und Retrieval |
Wichtiger als der Markenname ist die Frage: Passt die Lösung zu deinem Projekt, deiner Datenmenge, deiner Sprache und deinem Budget?
Braucht man dafür Mathematik?
Für die praktische Nutzung nicht zwingend. Du musst keine Formeln auswendig lernen, um zu verstehen, wie Vektor-Datenbanken im Alltag funktionieren.
Hilfreich ist aber dieses Grundverständnis:
- Inhalte werden in Zahlen umgewandelt
- ähnliche Bedeutungen liegen im Zahlenraum näher beieinander
- die Datenbank sucht diese Nähe effizient
Mehr musst du als Einsteiger zunächst nicht wissen.
Sind Vektor-Datenbanken auch für deutschsprachige Inhalte geeignet?
Ja, auf jeden Fall. Wichtig ist nur, dass das verwendete Embedding-Modell gut mit deutscher Sprache umgehen kann. Gerade bei deutschsprachigen Wissenssystemen lohnt es sich, die Qualität der Ergebnisse zu testen.
Denn Sprache ist nicht nur Grammatik. Auch Fachbegriffe, Synonyme und Satzbau spielen eine Rolle. Deshalb sollte man immer prüfen, wie gut die semantische Suche mit realen Nutzerfragen funktioniert.
Vektor-Datenbanken und Datenschutz
Sobald du mit echten Dokumenten, Kundeninformationen oder internen Daten arbeitest, spielt Datenschutz eine wichtige Rolle.
Wichtige Fragen sind dann:
- Welche Daten werden eingebettet?
- Werden sensible Inhalte gespeichert?
- Wo steht die Datenbank?
- Wer darf darauf zugreifen?
- Werden Daten verschlüsselt?
- Wie werden Löschung und Berechtigungen umgesetzt?
Gerade bei Unternehmensdaten sollte eine Vektor-Datenbank nie nur nach technischer Bequemlichkeit ausgewählt werden.
Wie lernt man das Thema am besten?
Am besten in dieser Reihenfolge:
1. Grundbegriffe verstehen
Vektor, Embedding, semantische Suche, Chunking, RAG.
2. Den Ablauf nachvollziehen
Wie kommt ein Text in die Datenbank und wie wird er später wiedergefunden?
3. Einfache Beispiele anschauen
Kurze Dokumente, Fragen und Suchergebnisse.
4. Praktische Systeme testen
Zum Beispiel kleine RAG-Demos oder semantische Suchsysteme.
5. Qualität bewerten lernen
Welche Treffer sind gut, welche schlecht und warum?
Zusammenfassung: Warum Vektor-Datenbanken so wichtig sind
Vektor-Datenbanken sind ein zentraler Baustein moderner KI-Anwendungen, weil sie Inhalte nicht nur nach Wörtern, sondern nach Bedeutung durchsuchbar machen. Genau dadurch werden intelligente Suchsysteme, Wissenschatbots und RAG-Anwendungen überhaupt erst wirklich nützlich.
Das Grundprinzip ist einfach: Inhalte werden in numerische Darstellungen umgewandelt, gespeichert und später über Ähnlichkeit wiedergefunden. Dahinter steckt zwar anspruchsvolle Technik, aber das Konzept ist auch für Einsteiger gut verständlich.
Wer sich mit KI, LLMs, semantischer Suche oder Wissenssystemen beschäftigt, sollte Vektor-Datenbanken unbedingt verstehen. Sie verbinden Sprache, Bedeutung und maschinelle Suche auf eine Weise, die klassische Datenbanken allein nicht leisten können.
Die wichtigsten Punkte auf einen Blick
| Kernpunkt | Bedeutung |
|---|---|
| Vektor-Datenbanken speichern Embeddings | Inhalte werden als numerische Bedeutungsdarstellung abgelegt |
| Sie ermöglichen semantische Suche | Nicht nur Wörter, sondern Sinn und Nähe werden erkannt |
| Sie sind zentral für RAG | Externe Wissensquellen können LLMs zugänglich gemacht werden |
| Chunking und Metadaten sind entscheidend | Gute Datenstruktur verbessert die Trefferqualität stark |
| Hybride Suche ist oft am besten | Keyword-Suche und Vektor-Suche ergänzen sich |
| Für KI-Projekte sind sie ein Schlüsselthema | Besonders bei Wissenssystemen und intelligenten Assistenten |
FAQ zu Vektor-Datenbanken
Was ist eine Vektor-Datenbank in einfachen Worten?
Eine Vektor-Datenbank ist eine spezielle Datenbank, die Inhalte wie Texte oder Bilder als Zahlenmuster speichert. Dadurch kann sie ähnliche Inhalte nach Bedeutung wiederfinden und nicht nur nach exakten Wörtern suchen.
Wofür braucht man Vektor-Datenbanken?
Sie werden vor allem für KI-Anwendungen gebraucht, etwa für semantische Suche, RAG-Systeme, intelligente Chatbots, Dokumentensuche oder Empfehlungssysteme.
Was ist der Unterschied zwischen Embeddings und Vektoren?
Im Alltag werden beide Begriffe oft fast gleich verwendet. Ein Embedding ist die vom KI-Modell erzeugte numerische Repräsentation eines Inhalts. Diese Repräsentation liegt als Vektor vor.
Können Vektor-Datenbanken auch mit deutschen Texten arbeiten?
Ja. Wichtig ist nur, dass ein passendes Embedding-Modell verwendet wird, das deutsche Sprache gut versteht. Dann lassen sich auch deutschsprachige Inhalte sehr effektiv semantisch durchsuchen.
Ersetzen Vektor-Datenbanken normale Datenbanken?
Nein, meistens nicht. Sie ergänzen klassische Datenbanken. Strukturierte Daten wie Kunden, Bestellungen oder Preise bleiben oft in normalen Datenbanken, während semantische Inhalte zusätzlich in einer Vektor-Datenbank gespeichert werden.
Was hat eine Vektor-Datenbank mit RAG zu tun?
Bei RAG sucht die Vektor-Datenbank passende Informationen aus Dokumenten oder Wissensquellen heraus. Diese Inhalte werden dann einem Sprachmodell als Kontext gegeben, damit es bessere und genauere Antworten erzeugen kann.
Ist eine Vektor-Datenbank dasselbe wie eine Suchmaschine?
Nicht ganz. Sie ist ein Spezialwerkzeug für semantische Ähnlichkeitssuche. Manche Suchsysteme kombinieren klassische Suche und Vektor-Suche, aber eine Vektor-Datenbank selbst ist in erster Linie für Embeddings und Similarity Search optimiert.
Braucht jede Website eine Vektor-Datenbank?
Nein. Sie ist besonders dann sinnvoll, wenn Inhalte intelligent nach Bedeutung durchsucht werden sollen. Für kleine einfache Webseiten ohne KI-Funktionen ist sie oft nicht notwendig.