KI-Modelle Funktionsweise einfach erklärt
KI-Modelle sind das Herzstück moderner Künstlicher Intelligenz. Sie stecken in Chatbots, Bildgeneratoren, Sprachassistenten, Übersetzungstools, Suchmaschinen und Empfehlungssystemen. Viele Menschen nutzen solche Systeme bereits täglich, ohne genau zu wissen, was im Hintergrund eigentlich passiert. Genau hier setzt dieser Beitrag an.
KI Modelle für beginner
Architektur, Funktionsweise und Bedeutung
KI-Modelle sind das Herzstück moderner Künstlicher Intelligenz. Sie stecken in Chatbots, Bildgeneratoren, Sprachassistenten, Übersetzungstools, Suchmaschinen und Empfehlungssystemen. Viele Menschen nutzen solche Systeme bereits täglich, ohne genau zu wissen, was im Hintergrund eigentlich passiert. Genau hier setzt dieser Beitrag an.
Wenn von „KI“ gesprochen wird, ist oft nicht die ganze Technologie gemeint, sondern ganz konkret ein KI-Modell. Ein Modell ist vereinfacht gesagt ein mathematisches System, das aus Daten gelernt hat und danach Vorhersagen, Einschätzungen oder neue Inhalte erzeugen kann. Es ist also nicht „intelligent“ wie ein Mensch, sondern arbeitet auf Basis von Mustern, Wahrscheinlichkeiten und Rechenprozessen.
Für Einsteiger wirkt das Thema oft kompliziert. Begriffe wie neuronale Netze, Parameter, Training, Inferenz oder Transformer klingen technisch und abstrakt. In Wahrheit lassen sich die Grundideen aber sehr gut verständlich erklären. Wer einmal das Prinzip hinter KI-Modellen verstanden hat, kann viele moderne Anwendungen deutlich besser einordnen.
In diesem Artikel lernst du Schritt für Schritt:
- was ein KI-Modell überhaupt ist
- wie KI-Modelle aus Daten lernen
- wie ein trainiertes Modell später arbeitet
- welche Arten von KI-Modellen es gibt
- warum Modelle Fehler machen
- wo ihre Grenzen liegen
- und warum große Sprachmodelle wie ChatGPT so funktionieren, wie sie funktionieren
Der Beitrag ist so aufgebaut, dass auch Leser ohne technisches Vorwissen mitkommen.
Was ist ein KI-Modell?
Ein KI-Modell ist ein System, das aus Beispielen gelernt hat. Es erkennt Zusammenhänge in Daten und kann dieses Wissen später anwenden. Statt feste Regeln einzeln einprogrammiert zu bekommen, entwickelt das Modell seine „Logik“ aus Trainingsdaten.
Ein einfaches Beispiel:
Wenn du einem Modell sehr viele Bilder von Katzen und Hunden zeigst, kann es mit der Zeit lernen, typische Merkmale zu erkennen. Es merkt sich nicht jedes Bild einzeln, sondern passt intern viele mathematische Werte so an, dass es neue Bilder besser einordnen kann.
Bei Textmodellen läuft es ähnlich. Ein Sprachmodell bekommt riesige Mengen Text und lernt dabei, welche Wörter, Satzteile und Bedeutungen oft zusammen auftreten. Dadurch kann es später Texte fortsetzen, Fragen beantworten oder Inhalte formulieren.
Ein KI-Modell ist also keine Datenbank mit fertigen Antworten. Es ist eher ein trainierter Mustererkenner.
Der Kern der Sache: KI lernt Muster aus Daten
Die Funktionsweise fast aller modernen KI-Modelle lässt sich auf einen Grundgedanken reduzieren:
Eingaben werden analysiert, Muster erkannt, Wahrscheinlichkeiten berechnet und daraus eine Ausgabe erzeugt.
Das klingt abstrakt, deshalb hilft ein Vergleich aus dem Alltag.
Stell dir vor, ein Kind lernt, Tiere zu unterscheiden. Es sieht viele Bilder, hört Erklärungen und macht Fehler. Nach und nach erkennt es: Katzen haben oft Schnurrhaare, bestimmte Ohrenformen und andere Körperproportionen als Hunde. Es lernt also nicht durch starre Formeln, sondern durch viele Beispiele.
Ein KI-Modell funktioniert ähnlich, nur mathematisch. Es bekommt viele Daten, vergleicht seine Vorhersagen mit der richtigen Lösung und verbessert sich Schritt für Schritt.
Aus welchen Bausteinen besteht ein KI-Modell?
Damit man die Funktionsweise versteht, sollte man die wichtigsten Grundbegriffe kennen.
Wichtige Begriffe im Überblick
| Begriff | Einfache Erklärung |
|---|---|
| Daten | Das Material, aus dem ein Modell lernt, zum Beispiel Texte, Bilder, Audios oder Tabellen |
| Training | Die Lernphase, in der das Modell Muster aus Daten aufnimmt |
| Parameter | Interne Zahlenwerte, die während des Trainings angepasst werden |
| Eingabe | Das, was du dem Modell gibst, zum Beispiel ein Satz oder ein Bild |
| Ausgabe | Das Ergebnis des Modells, zum Beispiel eine Antwort oder Klassifikation |
| Inferenz | Die Nutzungsphase eines bereits trainierten Modells |
| Fehlerfunktion | Misst, wie falsch oder wie gut eine Vorhersage war |
| Optimierung | Der Prozess, bei dem das Modell verbessert wird |
| Architektur | Der technische Aufbau des Modells, also wie es intern organisiert ist |
Diese Begriffe tauchen in fast allen Erklärungen zu KI auf. Wenn du sie einmal verstanden hast, wird vieles klarer.
Wie lernt ein KI-Modell?
Der Lernprozess eines KI-Modells heißt Training. Dabei wird das Modell mit vielen Beispielen gefüttert. Am Anfang ist seine Leistung oft schlecht, weil die internen Werte noch zufällig oder ungenau sind. Mit jeder Trainingsrunde werden diese Werte angepasst.
Das Grundprinzip des Trainings
Ein Modell erhält Eingabedaten. Danach erzeugt es eine Vorhersage. Diese Vorhersage wird mit der richtigen Lösung verglichen. Aus dem Unterschied wird berechnet, wie stark das Modell danebenlag. Anschließend werden interne Parameter verändert, damit der Fehler beim nächsten Mal kleiner wird.
Dieser Ablauf wiederholt sich oft millionen- oder sogar milliardenfach.
Training in einfachen Schritten
| Schritt | Was passiert? |
|---|---|
| 1. Daten eingeben | Das Modell bekommt Beispiele |
| 2. Vorhersage machen | Das Modell erzeugt eine erste Antwort |
| 3. Fehler berechnen | Die Vorhersage wird mit dem korrekten Ergebnis verglichen |
| 4. Parameter anpassen | Interne Werte werden verändert |
| 5. Wiederholen | Der Prozess läuft sehr oft, bis das Modell besser wird |
Man kann sich das wie einen Schüler vorstellen, der Übungsaufgaben löst, korrigiert wird und daraus lernt.
Was sind Parameter?
Parameter sind einer der wichtigsten Begriffe überhaupt. Sie sind die internen Stellschrauben eines KI-Modells. Bei modernen Modellen kann es davon Millionen, Milliarden oder sogar mehr geben.
Jeder dieser Werte beeinflusst, wie das Modell Eingaben verarbeitet. Während des Trainings werden diese Parameter angepasst, bis das Modell brauchbare Muster gelernt hat.
Ein großes Sprachmodell mit vielen Parametern hat nicht automatisch „echtes Verständnis“ wie ein Mensch. Es hat aber mehr Kapazität, komplexe Zusammenhänge in Daten abzubilden.
Ein einfaches Bild dafür
Stell dir ein riesiges Mischpult mit extrem vielen Reglern vor. Jeder Regler verändert einen kleinen Teil des Gesamtsystems. Beim Training werden diese Regler immer wieder minimal verstellt, bis das Ergebnis besser klingt. Bei KI ist das Ergebnis keine Musik, sondern zum Beispiel eine bessere Textantwort oder eine genauere Bilderkennung.
Was sind neuronale Netze?
Viele moderne KI-Modelle basieren auf neuronalen Netzen. Der Name ist von biologischen Nervenzellen inspiriert, aber die Technik ist viel einfacher und mathematischer als ein echtes Gehirn.
Ein neuronales Netz besteht aus vielen künstlichen „Neuronen“, die Informationen verarbeiten. Diese Einheiten sind in Schichten organisiert. Daten laufen von einer Eingabeschicht durch mehrere versteckte Schichten bis zur Ausgabeschicht.
Dabei werden Merkmale Schritt für Schritt weiterverarbeitet. Bei Bildern könnten frühe Schichten einfache Kanten erkennen, spätere Schichten Formen und ganz späte Schichten vielleicht ganze Objekte.
Typischer Aufbau
| Schicht | Aufgabe |
|---|---|
| Eingabeschicht | Nimmt Daten auf |
| Versteckte Schichten | Verarbeitet und kombiniert Merkmale |
| Ausgabeschicht | Liefert das Ergebnis |
Je nach Modelltyp kann dieses Netz sehr einfach oder extrem komplex sein.
Warum braucht KI so viele Daten?
Ein Modell lernt nicht aus dem Nichts. Es braucht Beispiele, um Muster zu erkennen. Je vielfältiger und hochwertiger die Daten sind, desto besser kann das Modell später generalisieren, also auf neue Fälle reagieren.
Ein Sprachmodell, das viel guten Text gesehen hat, kann Sprache flüssiger verarbeiten. Ein Bildmodell, das viele saubere Bildbeispiele gelernt hat, erkennt Motive zuverlässiger.
Allerdings gilt auch: Schlechte Daten führen oft zu schlechten Ergebnissen.
Qualität der Daten ist wichtiger als viele denken
| Gute Daten | Schlechte Daten |
|---|---|
| korrekt | fehlerhaft |
| vielfältig | einseitig |
| aktuell | veraltet |
| sauber strukturiert | voller Rauschen und Widersprüche |
| relevant | thematisch unpassend |
Viele Probleme bei KI entstehen nicht nur durch das Modell selbst, sondern durch unpassende Trainingsdaten.
Was bedeutet Inferenz?
Wenn ein Modell fertig trainiert ist und später tatsächlich genutzt wird, spricht man von Inferenz. Das ist der Moment, in dem der Nutzer eine Anfrage stellt und das Modell eine Antwort erzeugt.
Beim Training lernt das Modell.
Bei der Inferenz wendet es das Gelernte an.
Wenn du einen Chatbot fragst: „Erkläre mir Photosynthese“, dann läuft im Hintergrund Inferenz. Das Modell analysiert deine Eingabe, berechnet Wahrscheinlichkeiten und erzeugt dann die wahrscheinlich passende Antwort.
Wie funktioniert ein Sprachmodell?
Sprachmodelle sind für viele Nutzer besonders interessant, weil sie Texte schreiben, Fragen beantworten, übersetzen oder zusammenfassen können.
Im Kern lernt ein Sprachmodell, welches Wort oder welches Textelement mit hoher Wahrscheinlichkeit als Nächstes passt. Daraus entsteht der Eindruck eines flüssigen Gesprächs.
Sehr einfach erklärt
Wenn ein Modell den Satzanfang liest:
„Die Sonne geht im Osten …“
dann ist „auf“ deutlich wahrscheinlicher als „Kartoffel“. Das Modell arbeitet also mit Sprachmustern und Wahrscheinlichkeiten, nicht mit einem menschlichen Bewusstsein.
Natürlich ist ein modernes Sprachmodell viel komplexer als dieses Mini-Beispiel. Es berücksichtigt nicht nur ein einzelnes Wort davor, sondern oft große Teile des bisherigen Kontexts.
Was ein Sprachmodell intern ungefähr macht
| Schritt | Erklärung |
|---|---|
| Text zerlegen | Der Eingabetext wird in kleine Einheiten zerlegt, sogenannte Tokens |
| Kontext analysieren | Das Modell schaut, welche Bedeutung und Struktur im Text steckt |
| Wahrscheinlichkeiten berechnen | Es bewertet viele mögliche nächste Tokens |
| Ausgabe erzeugen | Es wählt das nächste passende Token |
| Wiederholen | Dieser Prozess läuft immer weiter, bis die Antwort fertig ist |
Deshalb entstehen Antworten Stück für Stück.
Was sind Tokens?
Sprachmodelle arbeiten meistens nicht direkt mit ganzen Wörtern, sondern mit Tokens. Ein Token kann ein ganzes Wort sein, ein Wortteil, ein Satzzeichen oder eine andere kleine Texteinheit.
Das ist wichtig, weil Modelle Text mathematisch verarbeiten müssen. Sie brauchen also eine Form, in der Sprache in Zahlen übersetzt werden kann.
Zum Beispiel könnte das Wort „unvorstellbar“ intern in mehrere Teile zerlegt werden. Dadurch kann das Modell Sprache flexibler verarbeiten, auch bei seltenen oder neuen Begriffen.
Wie versteht ein Modell Sprache, wenn es nur mit Zahlen arbeitet?
Das ist eine der spannendsten Fragen. Die Antwort lautet: Ein Modell „versteht“ Sprache nicht so wie ein Mensch, sondern übersetzt Sprache in mathematische Repräsentationen.
Wörter, Satzteile und Bedeutungen werden in Zahlenräume überführt. Ähnliche Begriffe liegen dort näher beieinander als unähnliche Begriffe. So kann das Modell Beziehungen lernen, zum Beispiel zwischen:
- König und Königin
- Berlin und Deutschland
- Hund und Tier
- Arzt und Krankenhaus
Diese mathematischen Bedeutungsräume bilden die Grundlage dafür, dass moderne Modelle semantische Zusammenhänge erkennen können.
Was ist der Unterschied zwischen Lernen und Anwenden?
Viele Einsteiger verwechseln Training und Benutzung. Deshalb ist diese Trennung besonders wichtig.
Training vs. Nutzung
| Bereich | Bedeutung |
|---|---|
| Training | Das Modell lernt aus großen Datenmengen |
| Nutzung/Inferenz | Das trainierte Modell beantwortet neue Anfragen |
Wenn du ChatGPT benutzt, trainierst du das Grundmodell normalerweise nicht neu. Du nutzt ein bereits trainiertes System. Deine Eingabe wird verarbeitet, aber das Modell selbst wird dadurch nicht jedes Mal dauerhaft umgelernt.
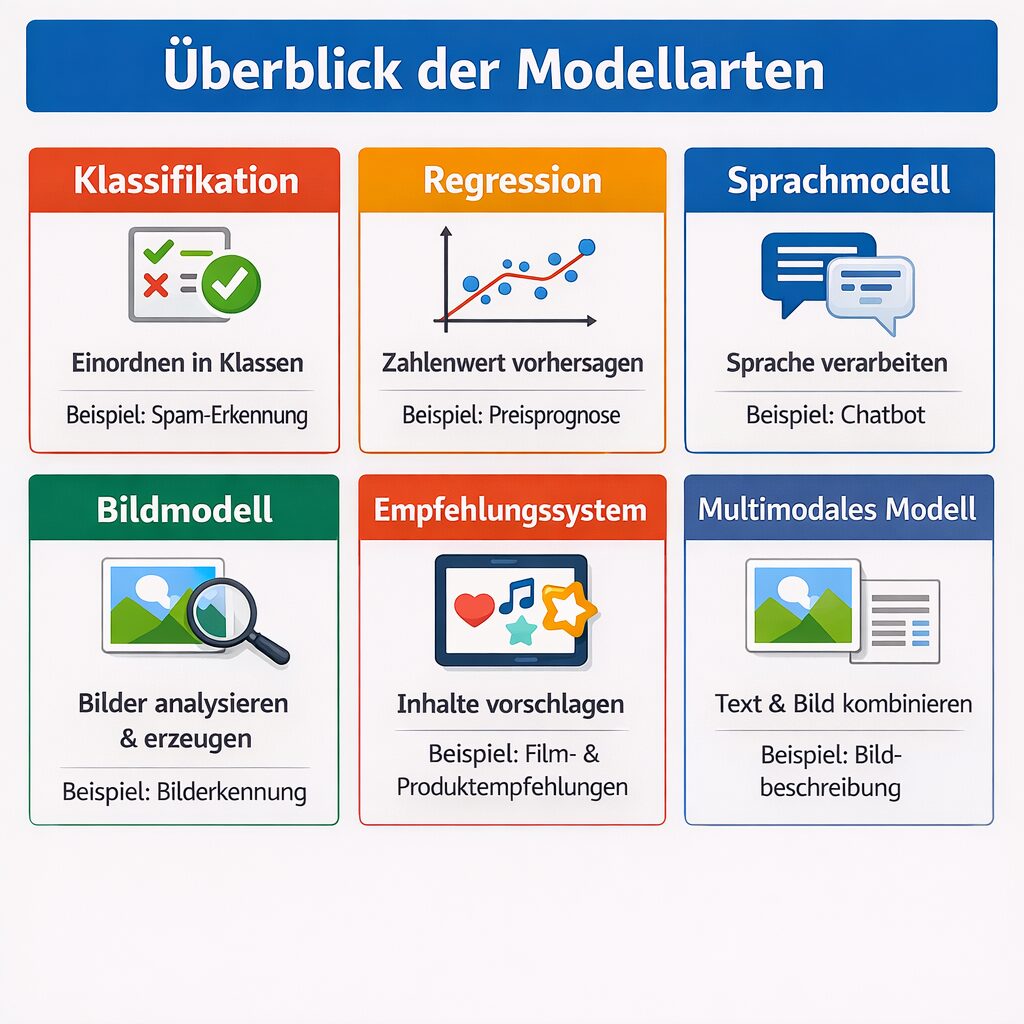
Welche Arten von KI-Modellen gibt es?
Nicht jedes KI-Modell ist gleich. Je nach Aufgabe gibt es unterschiedliche Modellarten.
1. Klassifikationsmodelle
Diese Modelle ordnen etwas in Kategorien ein.
Beispiel: E-Mail ist Spam oder kein Spam.
2. Regressionsmodelle
Diese Modelle sagen Zahlenwerte voraus.
Beispiel: Wie hoch wird der Mietpreis einer Wohnung wahrscheinlich sein?
3. Sprachmodelle
Diese Modelle verarbeiten Sprache.
Beispiel: Texte schreiben, übersetzen, zusammenfassen, Fragen beantworten.
4. Bildmodelle
Diese Modelle erkennen oder erzeugen Bilder.
Beispiel: Objekterkennung, medizinische Bildanalyse, Bildgenerierung.
5. Empfehlungssysteme
Diese Modelle schlagen Inhalte vor.
Beispiel: Welche Produkte, Filme oder Songs dir gefallen könnten.
6. Multimodale Modelle
Diese Modelle können mehrere Datentypen gleichzeitig verarbeiten, etwa Text und Bild.
Beispiel: Ein System beschreibt den Inhalt eines Fotos in natürlicher Sprache.
Überblick der Modellarten
| Modelltyp | Typische Aufgabe | Beispiel |
|---|---|---|
| Klassifikation | Einordnen in Klassen | Spam-Erkennung |
| Regression | Zahlenwert vorhersagen | Preisprognose |
| Sprachmodell | Sprache verarbeiten | Chatbot |
| Bildmodell | Bilder analysieren oder erzeugen | Bilderkennung |
| Empfehlungssystem | Inhalte vorschlagen | Streaming-Plattform |
| Multimodales Modell | Mehrere Datentypen kombinieren | Bild plus Text verstehen |
Was ist eine Modellarchitektur?
Die Architektur beschreibt den inneren Aufbau eines Modells. Sie legt fest, wie Daten verarbeitet werden und welche Strukturen dabei genutzt werden.
Bekannte Architekturen sind zum Beispiel:
- klassische neuronale Netze
- Convolutional Neural Networks für Bilder
- Recurrent Neural Networks für Sequenzen
- Transformer für moderne Sprachmodelle und viele andere Anwendungen
Die Architektur ist also das technische Design des Modells.
Warum sind Transformer so wichtig?
Transformer haben die KI-Welt stark verändert. Sie sind die Basis vieler moderner Sprachmodelle. Ihr großer Vorteil ist, dass sie Zusammenhänge im Text sehr gut erfassen können, auch über größere Entfernungen hinweg.
Frühere Systeme hatten oft Schwierigkeiten, langen Kontext sauber zu verarbeiten. Transformer lösen das deutlich besser, weil sie mithilfe von Aufmerksamkeitsmechanismen relevante Teile des Eingabetextes gewichten.
Einfach gesagt: Das Modell „achtet“ darauf, welche Wörter oder Satzteile im Zusammenhang besonders wichtig sind.
Was bedeutet Aufmerksamkeit bei KI?
Der englische Begriff dafür ist Attention. Gemeint ist kein menschliches Bewusstsein, sondern ein mathematischer Mechanismus.
Wenn ein Modell einen Satz verarbeitet, schaut es nicht auf alle Wörter gleich stark. Manche Wörter sind für das Verständnis wichtiger als andere. Der Attention-Mechanismus hilft dabei, relevante Beziehungen im Text zu erfassen.
Beispiel:
„Maria gab Anna ihr Buch zurück, weil sie es fertig gelesen hatte.“
Hier muss ein Modell den Zusammenhang zwischen „sie“ und der richtigen Person im Satz einschätzen. Genau solche Beziehungen kann Attention besser modellieren.
Warum machen KI-Modelle Fehler?
KI-Modelle wirken oft beeindruckend, sind aber nicht unfehlbar. Fehler gehören zum System dazu.
Häufige Ursachen für Fehler
| Ursache | Erklärung |
|---|---|
| Schlechte Daten | Das Modell lernt aus fehlerhaften oder einseitigen Beispielen |
| Zu wenig Daten | Das Modell hat nicht genug gelernt |
| Überanpassung | Das Modell merkt sich Trainingsdaten zu stark und generalisiert schlecht |
| Unklarer Kontext | Die Eingabe ist mehrdeutig oder unvollständig |
| Halluzinationen | Besonders Sprachmodelle erzeugen manchmal plausible, aber falsche Inhalte |
| Veraltetes Wissen | Das Modell kennt neue Entwicklungen nicht automatisch |
| Bias | Verzerrungen in den Daten führen zu verzerrten Ergebnissen |
Gerade bei Textmodellen ist es wichtig zu verstehen: Flüssige Sprache ist kein Beweis für Wahrheit.
Was ist Overfitting?
Overfitting bedeutet, dass ein Modell die Trainingsdaten zu stark „auswendig lernt“, statt allgemeine Muster zu erkennen. Dadurch funktioniert es bei bekannten Beispielen sehr gut, bei neuen aber schlechter.
Ein Schulvergleich hilft:
Ein Schüler merkt sich die Antworten alter Prüfungen wortwörtlich, versteht das Thema aber nicht wirklich. Sobald die Aufgaben leicht anders formuliert sind, macht er Fehler.
Genau das ist Overfitting.
Was ist Underfitting?
Underfitting ist das Gegenteil. Das Modell ist zu einfach oder wurde nicht gut genug trainiert. Es erkennt wichtige Muster nicht ausreichend und bleibt insgesamt schwach.
Ein gutes KI-Modell braucht also die richtige Balance: Es soll genug lernen, aber nicht bloß stumpf auswendig lernen.
Wie weiß man, ob ein Modell gut ist?
Modelle werden mit Testdaten überprüft, die sie idealerweise nicht im Training gesehen haben. So lässt sich messen, wie gut sie auf neue Fälle reagieren.
Je nach Aufgabe gibt es unterschiedliche Kennzahlen.
Typische Bewertungsmaße
| Aufgabe | Mögliche Kennzahl |
|---|---|
| Klassifikation | Genauigkeit, Präzision, Recall, F1-Score |
| Regression | Mittlerer Fehler, quadratischer Fehler |
| Sprachmodell | Perplexity, menschliche Bewertung, Benchmark-Tests |
| Bildmodell | Trefferquote, Objekterkennung, Segmentierungsqualität |
Bei realen Anwendungen reicht eine einzelne Zahl oft nicht aus. Wichtig ist immer auch, wie gut das Modell im praktischen Einsatz funktioniert.
Sind große Modelle automatisch besser?
Nicht immer. Große Modelle haben oft mehr Kapazität und können komplexere Aufgaben lösen. Sie benötigen aber auch mehr Rechenleistung, mehr Speicher und oft mehr Energie.
Außerdem ist größer nicht automatisch sinnvoller. Für viele praktische Anwendungsfälle ist ein kleineres, spezialisiertes Modell effizienter.
Vergleich: klein vs. groß
| Kleineres Modell | Größeres Modell |
|---|---|
| schneller | oft leistungsfähiger |
| günstiger | teurer |
| leichter lokal nutzbar | braucht mehr Rechenressourcen |
| gut für Spezialaufgaben | gut für breite, komplexe Aufgaben |
Die beste Wahl hängt also vom Ziel ab.
Lernen KI-Modelle wie Menschen?
Nein. Es gibt gewisse oberflächliche Ähnlichkeiten, etwa das Lernen aus Beispielen. Aber KI-Modelle haben kein menschliches Bewusstsein, keine echten Gefühle, keine Lebenserfahrung und kein tiefes Weltverständnis im menschlichen Sinn.
Sie arbeiten mit mathematischen Strukturen und statistischen Beziehungen. Das kann sehr leistungsfähig sein, ist aber etwas anderes als menschliches Denken.
Können KI-Modelle wirklich „verstehen“?
Das ist eine viel diskutierte Frage. Praktisch gesehen können Modelle erstaunlich gute Ergebnisse liefern, Zusammenhänge erkennen und komplexe Aufgaben bearbeiten. Trotzdem ist dieses „Verstehen“ nicht identisch mit menschlichem Verstehen.
Ein KI-Modell weiß nicht im menschlichen Sinn, was es „erlebt“. Es berechnet Muster und erzeugt darauf basierende Ausgaben. Das Resultat kann sehr überzeugend wirken, aber es bleibt ein technischer Prozess.
Wie entstehen Texte, Bilder oder Antworten?
Je nach Modelltyp unterschiedlich:
- Sprachmodelle erzeugen neue Textteile Token für Token
- Bildgeneratoren erzeugen Bildinhalte auf Basis gelernter Muster
- Klassifikationsmodelle geben Kategorien oder Wahrscheinlichkeiten aus
- Empfehlungssysteme sortieren und priorisieren Inhalte
Alle diese Systeme haben gemeinsam, dass sie aus Daten gelernt haben und dieses Wissen auf neue Eingaben anwenden.
Warum braucht KI so viel Rechenleistung?
Das Training großer Modelle ist extrem aufwendig. Millionen oder Milliarden Parameter müssen mit riesigen Datenmengen optimiert werden. Dafür braucht man spezialisierte Hardware wie GPUs oder andere Beschleuniger.
Auch die Nutzung großer Modelle kann rechenintensiv sein, besonders bei langen Eingaben oder komplexen Ausgaben.
Hauptgründe für hohen Rechenbedarf
| Grund | Erklärung |
|---|---|
| Viele Parameter | Mehr Rechenoperationen |
| Große Datenmengen | Mehr Trainingsaufwand |
| Komplexe Architektur | Mehr Verarbeitung pro Schritt |
| Lange Kontexte | Mehr Kontext muss berücksichtigt werden |
Warum sind KI-Modelle oft so beeindruckend?
Weil sie in bestimmten Bereichen extrem gut Muster erkennen. Wenn ein Modell mit genügend Daten und Rechenleistung trainiert wurde, kann es Aufgaben lösen, die früher als sehr schwer galten.
Dazu gehören zum Beispiel:
- flüssige Textgenerierung
- hochwertige Übersetzungen
- Bilderkennung
- Spracherkennung
- Zusammenfassungen
- Code-Vorschläge
- Inhaltsanalysen
Die Stärke moderner KI liegt besonders darin, große Datenmengen effizient auszuwerten und komplexe Strukturen darin nutzbar zu machen.
Wo liegen die Grenzen von KI-Modellen?
Trotz aller Fortschritte gibt es klare Grenzen.
Wichtige Grenzen
| Grenze | Bedeutung |
|---|---|
| Kein echtes Bewusstsein | KI erlebt nichts |
| Fehleranfälligkeit | Auch überzeugende Antworten können falsch sein |
| Datenabhängigkeit | Schlechte Daten verschlechtern Ergebnisse |
| Verzerrungen | Modelle können Vorurteile aus Daten übernehmen |
| Kein automatisches Echtzeitwissen | Ein Modell ist nicht automatisch aktuell |
| Kontextgrenzen | Sehr lange oder komplexe Zusammenhänge können problematisch werden |
Gerade für Wissensarbeit ist deshalb wichtig: KI ist ein Werkzeug, kein unfehlbarer Richter.
Was bedeutet Halluzination bei Sprachmodellen?
Halluzination ist ein Fachbegriff dafür, dass ein Sprachmodell etwas Falsches erfindet, obwohl die Antwort überzeugend klingt. Es kann zum Beispiel Quellen erfinden, Fakten vermischen oder Details sicher formulieren, die nicht stimmen.
Das passiert, weil das Modell auf Wahrscheinlichkeiten basiert. Es produziert sprachlich passende Antworten, nicht automatisch überprüfte Wahrheiten.
Für Nutzer bedeutet das:
KI-Antworten sollten bei wichtigen Themen immer geprüft werden.
Wie hängen Prompt und Modell zusammen?
Ein Prompt ist die Eingabe, mit der du ein Modell steuerst. Das Modell bringt seine trainierten Fähigkeiten mit, der Prompt lenkt diese Fähigkeiten in eine bestimmte Richtung.
Ein gutes Modell mit schlechtem Prompt liefert oft nur mittelmäßige Ergebnisse. Ein guter Prompt kann dagegen helfen, präziser, strukturierter und nützlicher zu antworten.
Die Qualität der Ausgabe hängt also stark von zwei Dingen ab:
- Wie gut das Modell ist
- Wie klar die Eingabe formuliert wurde
Wie arbeiten spezialisierte und allgemeine Modelle?
Allgemeine Modelle sind breit trainiert und können viele Aufgaben lösen. Spezialisierte Modelle sind für bestimmte Branchen oder Aufgaben optimiert.
Beispiele:
- ein allgemeines Sprachmodell für vielfältige Textaufgaben
- ein Medizinmodell für medizinische Fachtexte
- ein Finanzmodell für Marktanalysen
- ein Bildmodell für industrielle Qualitätskontrolle
Spezialisierte Modelle können in ihrem Bereich sehr stark sein, sind aber oft weniger flexibel.
KI-Modelle im Alltag
Viele Menschen nutzen KI bereits, ohne es bewusst wahrzunehmen.
Beispiele aus dem Alltag
| Anwendung | Was das Modell macht |
|---|---|
| Spamfilter | Erkennt unerwünschte E-Mails |
| Netflix oder YouTube | Empfiehlt Inhalte |
| Google Maps | Prognostiziert Routen und Zeiten |
| Sprachassistenten | Verarbeiten Spracheingaben |
| Übersetzungstools | Übersetzen Texte |
| Chatbots | Beantworten Fragen |
| Kamerasysteme | Erkennen Gesichter oder Objekte |
| Online-Shops | Zeigen passende Produkte |
So wird deutlich: KI-Modelle sind kein Zukunftsthema mehr, sondern längst Teil des digitalen Alltags.
Ein besonders wichtiges Missverständnis
Viele glauben, ein KI-Modell „wisse alles“. Das ist nicht richtig.
Ein Modell hat kein vollständiges Weltwissen wie eine perfekt gepflegte Datenbank. Es hat Muster aus Daten gelernt. Deshalb kann es sehr kompetent wirken, aber dennoch Fehler machen, Wissen vermischen oder bei Nischenthemen schwächer sein.
Gerade für Einsteiger ist dieser Punkt entscheidend. Wer KI richtig nutzen will, sollte sie weder unterschätzen noch überschätzen.
Ein einfaches Gesamtbild der Funktionsweise
Die Funktionsweise von KI-Modellen lässt sich stark vereinfacht so zusammenfassen:
Vom Rohdatenmaterial zur Antwort
| Phase | Was geschieht? |
|---|---|
| Datensammlung | Texte, Bilder oder andere Daten werden bereitgestellt |
| Training | Das Modell lernt Muster durch viele Wiederholungen |
| Parameteranpassung | Interne Werte werden optimiert |
| Fertiges Modell | Das trainierte System ist einsatzbereit |
| Eingabe durch Nutzer | Eine Frage, ein Bild oder eine andere Anfrage kommt herein |
| Inferenz | Das Modell verarbeitet die Eingabe |
| Ausgabe | Antwort, Klassifikation, Bild oder Empfehlung wird erzeugt |
Dieses Grundschema steckt hinter einem großen Teil moderner KI-Anwendungen.
Warum ist das Verständnis von KI-Modellen heute so wichtig?
Weil KI immer stärker in Bildung, Wirtschaft, Medien, Verwaltung, Medizin, Finanzen und Alltagssoftware eingebaut wird. Wer die Grundprinzipien versteht, kann Chancen besser erkennen und Risiken realistischer einschätzen.
Gerade im digitalen Zeitalter ist es wertvoll, nicht nur Nutzer zu sein, sondern auch die Mechanik hinter den Werkzeugen zu begreifen. Das hilft dabei, KI sinnvoll einzusetzen, Ergebnisse besser zu bewerten und Marketing-Versprechen kritisch zu hinterfragen.
So funktionieren KI-Modelle wirklich
KI-Modelle sind lernfähige mathematische Systeme, die aus großen Datenmengen Muster ableiten. Sie bekommen Eingaben, berechnen Wahrscheinlichkeiten und erzeugen daraus Ergebnisse. Während des Trainings werden interne Parameter so angepasst, dass das Modell immer bessere Vorhersagen oder Ausgaben liefert. In der späteren Nutzung wendet das Modell dieses Gelernte auf neue Anfragen an.
Das Entscheidende ist: KI-Modelle sind keine magischen Maschinen und auch keine denkenden Menschen. Sie sind hochentwickelte Werkzeuge zur Mustererkennung und Generierung. Genau darin liegt ihre Stärke – und auch ihre Grenze.
Wer die Funktionsweise versteht, kann moderne KI-Anwendungen deutlich besser einordnen. Und genau das ist heute wichtiger denn je.
FAQ: KI-Modelle Funktionsweise
Was ist ein KI-Modell einfach erklärt?
Ein KI-Modell ist ein trainiertes mathematisches System, das aus Daten Muster gelernt hat. Es kann danach neue Eingaben analysieren und passende Ausgaben erzeugen, zum Beispiel Antworten, Vorhersagen oder Klassifikationen.
Wie lernt ein KI-Modell?
Ein KI-Modell lernt durch Training. Es bekommt viele Beispiele, macht Vorhersagen, vergleicht diese mit den richtigen Ergebnissen und passt seine internen Parameter an. Dieser Vorgang wird sehr oft wiederholt.
Was sind Parameter bei KI-Modellen?
Parameter sind interne Zahlenwerte, die bestimmen, wie ein Modell Informationen verarbeitet. Beim Training werden diese Werte so verändert, dass das Modell bessere Ergebnisse liefert.
Was ist der Unterschied zwischen Training und Inferenz?
Training ist die Lernphase eines Modells. Inferenz ist die Nutzungsphase. Beim Training wird das Modell verbessert, bei der Inferenz beantwortet es neue Anfragen mit seinem bereits gelernten Wissen.
Warum machen KI-Modelle Fehler?
KI-Modelle arbeiten mit Wahrscheinlichkeiten und Mustern. Wenn Daten schlecht, unvollständig oder verzerrt sind, entstehen Fehler. Besonders Sprachmodelle können zudem plausible, aber falsche Antworten erzeugen.
Sind große KI-Modelle immer besser?
Nicht zwingend. Große Modelle sind oft leistungsfähiger, aber auch teurer und rechenintensiver. Für viele Aufgaben sind kleinere, spezialisierte Modelle sinnvoller.
Können KI-Modelle wirklich denken?
Nein, nicht wie Menschen. KI-Modelle haben kein Bewusstsein und keine echten Erfahrungen. Sie verarbeiten Daten mathematisch und erzeugen daraus passende Ergebnisse.
Wo werden KI-Modelle eingesetzt?
KI-Modelle werden in Chatbots, Suchmaschinen, Spamfiltern, Bildanalyse, Übersetzungen, Empfehlungssystemen, Sprachassistenten, Medizinsoftware, Finanztools und vielen anderen digitalen Anwendungen eingesetzt.