Fine-Tuning einfach erklärt
Fine-Tuning ist eines der am häufigsten missverstandenen Themen im Bereich Künstliche Intelligenz. Viele Einsteiger hören den Begriff früh, oft zusammen mit Large Language Models, Chatbots, RAG oder Embeddings, und nehmen an, dass man ein Modell einfach „mit eigenen Daten füttert“, damit es alles besser weiß.
Fine Tuning
Wann man ein KI-Modell nachtrainiert und wann RAG die bessere Wahl ist
Fine-Tuning einfach erklärt: Wann man ein KI-Modell nachtrainiert und wann RAG die bessere Wahl ist
Fine-Tuning ist eines der am häufigsten missverstandenen Themen im Bereich Künstliche Intelligenz. Viele Einsteiger hören den Begriff früh, oft zusammen mit Large Language Models, Chatbots, RAG oder Embeddings, und nehmen an, dass man ein Modell einfach „mit eigenen Daten füttert“, damit es alles besser weiß. Genau hier beginnt das Problem: In der Praxis ist Fine-Tuning nicht dasselbe wie Wissensspeicherung, nicht dasselbe wie Dokumentensuche und auch nicht automatisch die beste Lösung.
Wer verstehen will, wann Fine-Tuning sinnvoll ist und wann man stattdessen lieber auf RAG setzt, braucht ein klares Grundverständnis. Genau das vermittelt dieser Beitrag. Du lernst Schritt für Schritt, was Fine-Tuning ist, wie es technisch funktioniert, worin der Unterschied zum Pretraining liegt, wann Fine-Tuning sinnvoll sein kann, welche Kosten und Risiken entstehen und für wen sich der Aufwand überhaupt lohnt.
Der Artikel ist so aufgebaut, dass auch Leser ohne tiefes Vorwissen das Thema von Grund auf verstehen können. Gleichzeitig ist er fachlich stark genug, um als sauberer Wissensbeitrag auf einer KI-Ratgeber-Webseite zu funktionieren.
Was ist Fine-Tuning?
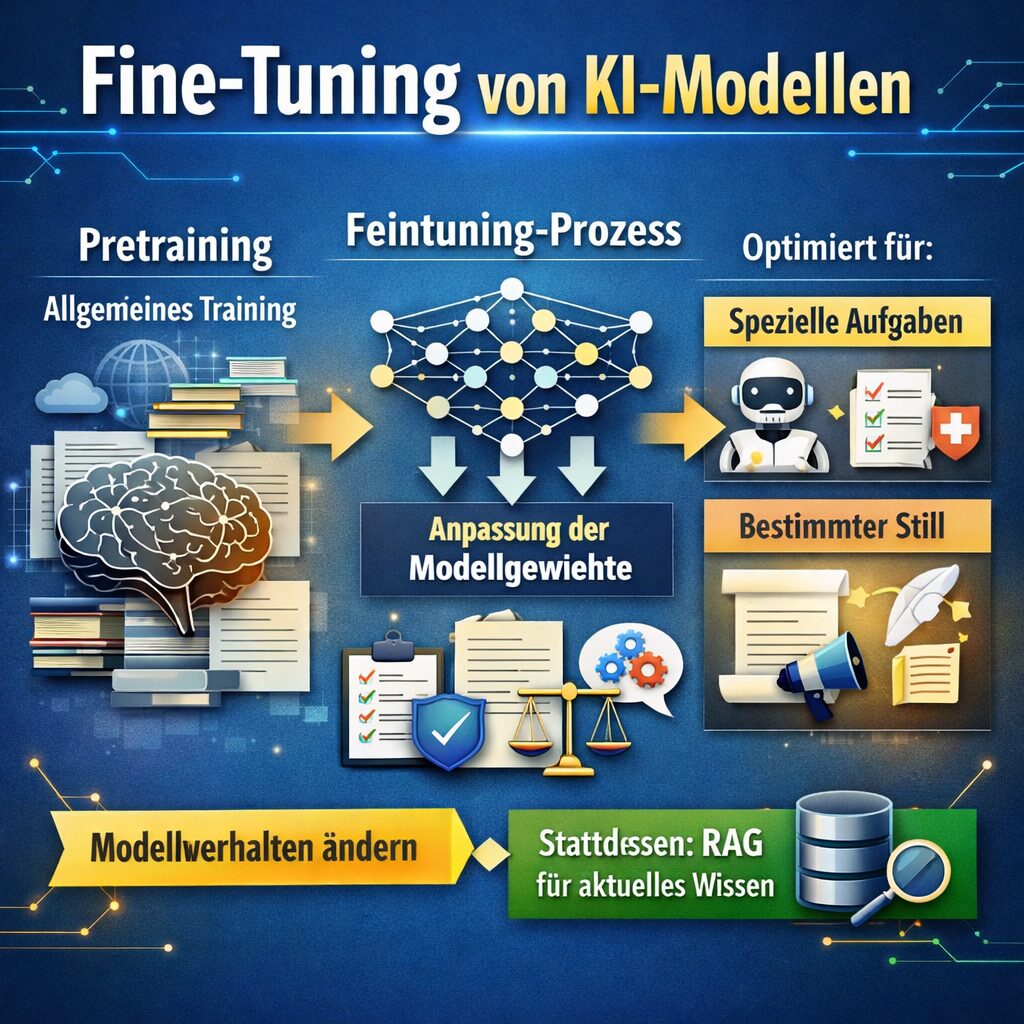
Fine-Tuning bedeutet, dass ein bereits vortrainiertes KI-Modell gezielt weitertrainiert wird, damit es sich in bestimmten Aufgaben, Stilen, Formaten oder Fachbereichen besser verhält.
Wichtig ist dabei das Wort bereits vortrainiert. Ein modernes KI-Modell wird nicht bei null begonnen. Es existiert schon als großes Basismodell, das sehr viel allgemeines Sprachwissen, Mustererkennung und statistische Zusammenhänge gelernt hat. Beim Fine-Tuning wird dieses vorhandene Modell anschließend auf eine spezielle Aufgabe oder ein spezielles Ziel angepasst.
Vereinfacht gesagt ist Fine-Tuning also:
ein Nachtraining eines bestehenden Modells für einen engeren Zweck
Das kann zum Beispiel bedeuten, dass ein Modell:
- juristische Texte besser formulieren soll
- Support-Antworten in einem bestimmten Stil geben soll
- medizinische Fachsprache besser verstehen soll
- strukturierte Ausgaben in einem festen Format liefern soll
- in einer bestimmten Tonalität oder Markenstimme schreiben soll
Fine-Tuning ist also keine allgemeine „Wissensablage“, sondern eine gezielte Verhaltensanpassung.
Warum viele Fine-Tuning falsch verstehen
Viele Nutzer denken zunächst:
„Ich habe eigene PDFs, Dokumente oder Produktdaten. Also muss ich das Modell fine-tunen.“
Das ist in sehr vielen Fällen nicht die beste Lösung.
Wenn du möchtest, dass ein Modell auf aktuelle oder interne Inhalte zugreift, ist häufig RAG die bessere Wahl. Fine-Tuning speichert nicht einfach sauber und kontrolliert neues Faktenwissen wie eine Datenbank. Es verändert das Modellverhalten statistisch. Das ist ein großer Unterschied.
Genau deshalb sollte man Fine-Tuning nicht mit diesen Dingen verwechseln:
- Dokumentenspeicherung
- Wissensdatenbank
- Dateizugriff
- semantische Suche
- aktuelle Informationsversorgung
- kontrollierte Quellenabfrage
Für all das ist oft RAG oder ein hybrides Retrieval-System geeigneter.
Was bedeutet „ein Modell nachtrainieren“ konkret?
Ein Basismodell hat beim ursprünglichen Training bereits sehr viele Sprachmuster gelernt. Beim Fine-Tuning werden die internen Gewichte des Modells erneut angepasst, damit es bei bestimmten Eingaben häufiger die gewünschten Ausgaben produziert.
Das Modell lernt dabei nicht wie ein Mensch bewusst neue Wahrheiten, sondern es verändert Wahrscheinlichkeiten im inneren Netz. Bestimmte Formulierungen, Strukturen, Prioritäten oder Antwortmuster werden dadurch wahrscheinlicher.
Ein einfaches Beispiel
Stell dir vor, ein allgemeines Sprachmodell kann schon gut schreiben. Du möchtest nun, dass es:
- Produktbeschreibungen immer im Stil deiner Marke schreibt
- immer eine klare Struktur mit Überschrift, Nutzen, Einsatzbereich und Fazit liefert
- technische Begriffe aus deinem Fachgebiet besser einordnet
- keine lockeren Umgangsformen benutzt
Dann kann Fine-Tuning helfen, genau dieses Verhalten stärker zu verankern.
Fine-Tuning in einem Satz
Fine-Tuning ist die gezielte Anpassung eines vortrainierten KI-Modells, damit es in einer speziellen Aufgabe, Domäne, Sprache, Struktur oder Tonalität besser funktioniert.
Wie funktioniert Fine-Tuning technisch?
Um Fine-Tuning wirklich zu verstehen, hilft ein Blick auf die technische Grundidee. Du musst dafür keine tiefen mathematischen Kenntnisse haben. Wichtig ist nur, dass du den Ablauf nachvollziehen kannst.
1. Es gibt ein vortrainiertes Modell
Am Anfang steht ein Basismodell, das bereits auf sehr großen Datenmengen trainiert wurde. Dieses Modell kann Sprache verstehen und erzeugen, weil es beim Training sehr viele Muster gesehen hat.
2. Es werden spezielle Trainingsdaten vorbereitet
Danach erstellt man einen Datensatz, der zeigt, wie das Modell sich künftig verhalten soll. Dieser Datensatz besteht häufig aus:
- Eingaben und gewünschten Antworten
- Anweisungen und idealen Ausgaben
- Beispielen für bestimmte Formate
- Fachtexten mit korrekten Zielmustern
- Dialogpaaren
- Klassifizierungsbeispielen
3. Das Modell wird mit diesen Beispielen weitertrainiert
Das Modell erhält neue Beispiele und vergleicht seine eigene Ausgabe mit der gewünschten Zielausgabe. Aus der Abweichung wird ein Fehler berechnet. Anschließend werden die Modellgewichte leicht angepasst, damit ähnliche Fehler künftig seltener passieren.
4. Dieser Prozess wird mehrfach wiederholt
Das Training läuft nicht nur einmal, sondern in vielen Schritten. So verstärkt das Modell nach und nach die gewünschten Muster.
5. Am Ende entsteht eine spezialisierte Modellvariante
Nach dem Fine-Tuning steht keine völlig neue Intelligenz bereit, sondern eine angepasste Version des Basismodells mit stärkerer Spezialisierung.
Was genau wird beim Fine-Tuning verändert?
Im Hintergrund bestehen KI-Modelle aus sehr vielen Parametern. Diese Parameter bestimmen, wie das Modell Eingaben interpretiert und welche Ausgaben es bevorzugt.
Beim Fine-Tuning werden diese Parameter weiter angepasst. Je nach Methode geschieht das vollständig oder nur teilweise.
Vereinfacht gesagt
Das Modell lernt nicht bloß neue „Dateien“, sondern seine internen Wahrscheinlichkeiten und Reaktionsmuster verschieben sich.
Dadurch wird es zum Beispiel:
- stilistisch konsistenter
- formatgenauer
- domänenspezifischer
- anweisungsstärker
- besser auf definierte Spezialaufgaben abgestimmt
Welche Arten von Fine-Tuning gibt es?
Nicht jedes Fine-Tuning läuft gleich ab. Es gibt mehrere Ansätze, die sich in Aufwand, Kosten und Tiefe unterscheiden.
Full Fine-Tuning
Hier werden sehr viele oder sogar alle relevanten Modellgewichte angepasst. Das kann leistungsfähig sein, ist aber oft teuer und technisch aufwendiger.
Parameter-Efficient Fine-Tuning
Hier wird nur ein kleiner Teil des Modells angepasst oder es werden Zusatzmodule verwendet. Dadurch sinkt der Rechenaufwand deutlich. Solche Ansätze sind in der Praxis oft attraktiver.
Instruction Fine-Tuning
Hier wird das Modell mit vielen Beispielen trainiert, um Anweisungen besser zu verstehen und gewünschte Antwortformen zuverlässiger zu liefern.
Domain Fine-Tuning
Hier wird ein Modell auf eine spezielle Fachdomäne angepasst, etwa Recht, Medizin, Finanzen oder technischen Support.
Style Fine-Tuning
Hier geht es eher um Tonalität, Markenstimme, Schreibstil oder bestimmte Ausgabeformate.
Technischer Ablauf von Fine-Tuning im Überblick
| Schritt | Was passiert? |
|---|---|
| 1 | Ein vortrainiertes Basismodell wird ausgewählt |
| 2 | Trainingsdaten werden gesammelt und bereinigt |
| 3 | Daten werden in ein geeignetes Trainingsformat gebracht |
| 4 | Das Modell erhält Eingaben und Zielausgaben |
| 5 | Fehler zwischen Modellantwort und Zielantwort werden berechnet |
| 6 | Modellgewichte werden angepasst |
| 7 | Der Prozess wird über viele Trainingsschritte wiederholt |
| 8 | Das Ergebnis wird getestet, validiert und später produktiv eingesetzt |
Was ist der Unterschied zwischen Pretraining und Fine-Tuning?
Dieser Unterschied ist zentral. Viele Nutzer werfen beide Begriffe durcheinander.
Was ist Pretraining?
Pretraining ist das große Grundtraining eines Modells auf riesigen Datenmengen. In dieser Phase lernt das Modell allgemeine Sprachmuster, Wissen, Zusammenhänge, Grammatik, Stilvarianten und statistische Beziehungen zwischen Wörtern, Sätzen und Konzepten.
Das ist die Phase, in der ein Basismodell seine grundlegenden Fähigkeiten entwickelt.
Was ist Fine-Tuning im Vergleich dazu?
Fine-Tuning kommt nach dem Pretraining. Es ist deutlich kleiner, gezielter und spezialisierter. Das Modell wird nicht mehr allgemein aufgebaut, sondern für einen engeren Anwendungsfall nachjustiert.
Der Unterschied einfach erklärt
Pretraining ist wie eine lange allgemeine Ausbildung. Fine-Tuning ist wie eine Spezialisierung nach der Grundausbildung.
Beispiel aus dem Alltag
- Pretraining: Jemand studiert viele Jahre allgemein Medizin.
- Fine-Tuning: Danach spezialisiert sich die Person auf Radiologie.
Die Person ist danach nicht ein völlig neuer Mensch, sondern gezielter auf einen bestimmten Bereich trainiert.
Pretraining vs. Fine-Tuning in der Tabelle
| Merkmal | Pretraining | Fine-Tuning |
|---|---|---|
| Ziel | Allgemeine Fähigkeiten aufbauen | Spezielle Fähigkeiten anpassen |
| Datenmenge | Sehr groß | Deutlich kleiner |
| Aufwand | Extrem hoch | Vergleichsweise geringer |
| Wissenstiefe | Breites Grundwissen | Engere Spezialisierung |
| Zeitpunkt | Erste große Trainingsphase | Nach dem Basistraining |
| Typischer Zweck | Basismodell erschaffen | Verhalten optimieren |
Was lernt ein Modell beim Fine-Tuning wirklich?
Das ist eine sehr wichtige Frage, weil hier oft falsche Erwartungen entstehen.
Ein Modell lernt beim Fine-Tuning in erster Linie:
- gewünschte Antwortmuster
- bevorzugte Formulierungen
- bessere Leistung bei einer bestimmten Aufgabe
- fachliche Schwerpunktsetzung
- spezifische Ausgabeformate
- gewünschte Reaktionsweisen
Es lernt dabei aber nicht automatisch eine sauber aktualisierbare Wissensbasis wie in einer Datenbank. Das Wissen ist nicht einfach transparent als Dokument abgelegt, sondern statistisch im Modellverhalten verankert.
Das bedeutet auch: Fine-Tuning ist schlechter geeignet, wenn du ständig neue Fakten, aktuelle Produktdaten oder laufend wechselnde Dokumente einpflegen willst.
Wofür ist Fine-Tuning besonders gut geeignet?
Fine-Tuning ist stark, wenn du das Verhalten eines Modells gezielt verändern möchtest.
Gute Einsatzbereiche
- fest definierte Textformate
- spezialisierte Klassifikation
- festes Antwortschema
- Markenstimme oder Unternehmensstil
- spezielle Fachsprache
- strukturierte Extraktion
- dialogische Verhaltensmuster
- wiederkehrende Aufgaben mit ähnlicher Logik
Beispielhafte Anwendungsfälle
| Anwendungsfall | Warum Fine-Tuning sinnvoll sein kann |
|---|---|
| Support-Antworten im festen Ton | Stil und Format lassen sich konsistent trainieren |
| Juristische Textklassifikation | Spezialmuster und Fachsprache können verbessert werden |
| Extraktion aus Formularen | Einheitliche Zielstruktur lässt sich gut antrainieren |
| Medizinische Kategorisierung | Fachdomäne kann gezielt gestärkt werden |
| Markenkommunikation | Tonalität und Ausdruck können stabilisiert werden |
| Interne Textvorlagen | Gewünschte Struktur wird zuverlässiger eingehalten |
Wofür ist Fine-Tuning eher ungeeignet?
Fine-Tuning ist meist die falsche Lösung, wenn du eigentlich etwas anderes willst.
Typische Fälle, in denen Fine-Tuning oft nicht ideal ist
- aktuelle Dokumente integrieren
- Unternehmenswissen durchsuchen
- PDFs oder Webseiten direkt nutzbar machen
- häufig wechselnde Daten einbinden
- Quellen transparent nachweisen
- Wissensstände schnell aktualisieren
- Fragen auf Basis konkreter Dokumente beantworten
Für diese Anwendungsfälle ist RAG sehr oft die bessere Wahl.
Was ist RAG noch einmal kurz?
RAG steht für Retrieval-Augmented Generation. Dabei wird das Modell nicht primär umtrainiert, sondern erhält bei der Anfrage passende Informationen aus einer externen Wissensquelle, etwa aus einer Vektor-Datenbank oder Dokumentensammlung.
Vereinfacht gesagt:
- Fine-Tuning verändert das Modell
- RAG liefert dem Modell externe Informationen zur Laufzeit
Fine-Tuning vs. RAG: Der zentrale Unterschied
Das ist der wichtigste Abschnitt dieses Artikels, denn genau hier liegt die praktische Entscheidung.
Fine-Tuning verändert das Verhalten des Modells
Fine-Tuning ist vor allem sinnvoll, wenn das Modell sich anders ausdrücken, anders strukturieren oder in Spezialaufgaben besser reagieren soll.
RAG erweitert das Wissen des Modells zur Laufzeit
RAG ist sinnvoll, wenn das Modell auf externe Inhalte zugreifen soll, etwa auf:
- eigene Dokumente
- interne Wissensdatenbanken
- aktuelle Produktdaten
- juristische Texte
- Support-Artikel
- Handbücher
- Wikis
- laufend aktualisierte Inhalte
Die Faustregel
Wenn du Verhalten ändern willst, denke an Fine-Tuning.
Wenn du Wissen abrufbar machen willst, denke zuerst an RAG.
Fine-Tuning vs. RAG in der Übersicht
| Frage | Fine-Tuning | RAG |
|---|---|---|
| Was wird verändert? | Das Modell selbst | Der Kontext zur Anfrage |
| Gut für aktuelles Wissen? | Eher nein | Ja |
| Gut für Stil und Format? | Ja | Nur begrenzt |
| Gut für Dokumentenfragen? | Eher nein | Ja |
| Leicht aktualisierbar? | Nein, erneutes Training nötig | Ja, Datenquelle kann aktualisiert werden |
| Quellen nachvollziehbar? | Schwierig | Deutlich besser |
| Geeignet für Fachwissen mit wechselnden Inhalten? | Nur begrenzt | Sehr gut |
| Geeignet für feste Spezialaufgaben? | Sehr gut | Teilweise |
Ein praktisches Beispiel: Wann Fine-Tuning sinnvoll ist
Angenommen, ein Unternehmen möchte, dass ein Modell immer Support-Antworten in dieser Struktur liefert:
- kurze empathische Einleitung
- klare Problemanalyse
- Schritt-für-Schritt-Lösung
- Sicherheitshinweis
- Abschluss mit Handlungsoption
Zusätzlich soll der Stil sachlich, höflich und markenkonform sein.
Das ist ein klassischer Fall, in dem Fine-Tuning sinnvoll sein kann. Hier geht es weniger um neue Wissensquellen, sondern um konsistentes Verhalten und Ausgabequalität.
Ein praktisches Beispiel: Wann RAG sinnvoller ist
Nun stell dir vor, dasselbe Unternehmen hat:
- 3.000 Support-Artikel
- laufend aktualisierte Produktdokumentation
- interne Prozessregeln
- neue Versionen der Software alle paar Wochen
Jetzt möchte man, dass ein Chatbot Antworten mit Bezug auf diese Inhalte gibt.
Hier ist RAG meist die bessere Wahl. Denn die Informationen ändern sich laufend. Es wäre unpraktisch, das Modell ständig neu zu fine-tunen. Stattdessen holt ein RAG-System passende Dokumentabschnitte zur Anfrage.
Warum viele Projekte Fine-Tuning überschätzen
Fine-Tuning klingt für Einsteiger oft nach der „mächtigen Profi-Lösung“. In Wirklichkeit ist es häufig nicht die erste, sondern eher die zweite oder dritte Ausbaustufe.
Viele Projekte brauchen zunächst viel dringender:
- saubere Daten
- gute Dokumentenstruktur
- Retrieval
- bessere Prompts
- Metadaten
- gute Chunking-Strategien
- semantische Suche
- Evaluierung der Antworten
Oft entsteht der Eindruck, das Modell sei „zu dumm“, obwohl in Wahrheit die Datenbasis oder der Retrieval-Teil schlecht umgesetzt ist.
Wann man zuerst RAG prüfen sollte
RAG sollte oft zuerst geprüft werden, wenn:
- Dokumente oder Wissensquellen existieren
- Inhalte aktualisiert werden müssen
- Nachweise und Quellen wichtig sind
- das Modell mit internen Daten arbeiten soll
- Fachinhalte nicht statisch sind
- Antworten überprüfbar bleiben sollen
In vielen Business-Projekten ist RAG deshalb der praktischere erste Schritt.
Kann man Fine-Tuning und RAG kombinieren?
Ja, und das ist in professionellen Systemen sogar sehr häufig sinnvoll.
Ein Modell kann zum Beispiel:
- per Fine-Tuning auf einen bestimmten Stil trainiert werden
- und zusätzlich per RAG auf aktuelle Dokumente zugreifen
Dann übernimmt Fine-Tuning die Verhaltensseite und RAG die Wissensseite.
Beispiel
Ein juristischer KI-Assistent könnte:
- per Fine-Tuning lernen, präzise und formal zu formulieren
- per RAG aktuelle Gesetzestexte, interne Richtlinien und Dokumente abrufen
Das ist oft deutlich stärker als nur eine der beiden Methoden allein.
Wie sieht ein typischer Fine-Tuning-Datensatz aus?
Die Qualität des Fine-Tunings hängt stark von den Trainingsdaten ab. Ein schlechter Datensatz führt fast immer zu schwachen Ergebnissen.
Typisch sind strukturierte Beispiele wie:
- Anweisung → gewünschte Antwort
- Frage → korrekte Antwort
- Text → Klassifikation
- Eingabe → gewünschtes JSON-Format
- Kundennachricht → professionelle Support-Antwort
Einfache schematische Darstellung
| Eingabe | Gewünschte Ausgabe |
|---|---|
| „Schreibe eine Support-Antwort zu einem verspäteten Versand.“ | Höfliche, markenkonforme Antwort mit Entschuldigung und Lösungsschritten |
| „Ordne diesen Text als Beschwerde oder Anfrage ein.“ | „Beschwerde“ |
| „Extrahiere Name, Datum und Rechnungsnummer.“ | Strukturierte Felder mit den drei Werten |
Je sauberer, konsistenter und qualitativ hochwertiger diese Beispiele sind, desto besser kann das Modell lernen.
Welche Datenqualität braucht man für Fine-Tuning?
Sehr gute. Fine-Tuning verstärkt Muster. Wenn dein Datensatz unklar, widersprüchlich oder schlampig ist, trainierst du dem Modell genau diese Probleme an.
Wichtige Qualitätskriterien
- klare Zielstruktur
- konsistente Formatierung
- fachlich korrekte Antworten
- keine unnötigen Widersprüche
- ausreichend viele gute Beispiele
- klare Abgrenzung der Aufgabe
- repräsentative Daten für den echten Einsatz
Was kann beim Fine-Tuning schiefgehen?
Fine-Tuning ist leistungsfähig, aber auch riskant. Vor allem dann, wenn es ohne klare Zieldefinition oder mit schlechten Daten gemacht wird.
Typische Risiken
Overfitting
Das Modell passt sich zu stark an die Trainingsbeispiele an und verallgemeinert schlecht.
Stilverschlechterung
Das Basismodell war vielleicht sprachlich sehr stark. Schlechte Trainingsdaten können die Qualität sogar verschlechtern.
Halluzinationen bleiben möglich
Fine-Tuning löst nicht automatisch das Halluzinationsproblem. Ein feinjustiertes Modell kann weiterhin falsche Fakten erzeugen.
Veraltetes Wissen
Wenn sich die Inhalte ändern, bleibt das fine-getunte Modell schnell zurück.
Hohe Wartung
Neue Anforderungen können erneutes Fine-Tuning nötig machen.
Falsche Erwartungshaltung
Viele Teams hoffen auf Wissensintegration, obwohl eigentlich ein Retrieval-System gebraucht wird.
Kosten, Aufwand und Risiken von Fine-Tuning
Dieser Punkt ist in der Praxis sehr wichtig. Fine-Tuning klingt oft attraktiv, ist aber nie nur ein Knopfdruck.
Welche Kosten entstehen?
Die Kosten hängen stark von Modellgröße, Trainingsmethode, Infrastruktur und Datensatz ab. Auch wenn man keine konkreten Preislisten verallgemeinern sollte, lassen sich die Kostenarten gut erklären.
Typische Kostenblöcke
- Datensammlung
- Datenbereinigung
- Annotation und Qualitätskontrolle
- technische Vorbereitung der Trainingsdaten
- Rechenressourcen für das Training
- Evaluierung
- Tests
- Deployment
- Monitoring
- spätere Nachbesserungen
Warum Daten oft teurer sind als das Training selbst
Viele Einsteiger denken beim Fine-Tuning vor allem an GPU-Kosten. In der Realität ist die größte Herausforderung oft die Datenarbeit.
Denn gute Trainingsdaten müssen:
- fachlich korrekt sein
- sauber formatiert sein
- repräsentativ für den Use Case sein
- konsistent sein
- geprüft sein
Wenn diese Grundlage fehlt, bringt auch ein teures Training wenig.
Aufwand von Fine-Tuning in der Praxis
| Bereich | Typischer Aufwand |
|---|---|
| Zieldefinition | Hoch, weil der Use Case sehr klar sein muss |
| Datenaufbereitung | Sehr hoch |
| Technische Umsetzung | Mittel bis hoch |
| Modellbewertung | Hoch |
| Wartung | Mittel bis hoch |
| Aktualisierung | Oft aufwendig |
Risiken im Überblick
| Risiko | Erklärung |
|---|---|
| Schlechte Trainingsdaten | Führen zu schlechterem Modellverhalten |
| Falscher Anwendungsfall | Fine-Tuning wird genutzt, obwohl RAG besser wäre |
| Überanpassung | Modell funktioniert nur in engen Beispielen gut |
| Hohe Folgekosten | Jede Anpassung kann neue Trainingsläufe auslösen |
| Fehlende Transparenz | Modellwissen ist nicht so einfach prüfbar wie Dokumentenquellen |
| Veraltete Inhalte | Fakten ändern sich schneller als das Modell nachtrainiert wird |
Wie entscheidet man zwischen Fine-Tuning und RAG?
Hier hilft ein systematischer Blick auf das eigentliche Ziel.
Frage 1: Geht es um Verhalten oder Wissen?
Wenn es um Stil, Struktur, Format oder Reaktionsmuster geht, spricht das eher für Fine-Tuning.
Wenn es um Inhalte, Dokumente, Fakten oder aktuelle Informationen geht, spricht das eher für RAG.
Frage 2: Ändern sich die Informationen regelmäßig?
Wenn ja, ist RAG meistens besser. Fine-Tuning ist träge, wenn Wissen oft aktualisiert werden muss.
Frage 3: Brauchst du nachvollziehbare Quellen?
Wenn Quellen wichtig sind, ist RAG meist klar im Vorteil. Dort kann man Dokumente, Passagen und Referenzen gezielt zurückgeben.
Frage 4: Ist die Aufgabe stark wiederholbar und klar definiert?
Wenn ja, kann Fine-Tuning sehr interessant sein.
Frage 5: Hast du genug gute Trainingsdaten?
Ohne gute Daten ist Fine-Tuning meist keine gute Idee.
Einfache Entscheidungslogik
| Situation | Eher Fine-Tuning | Eher RAG |
|---|---|---|
| Markenton konsistent machen | Ja | Nein |
| Aktuelle Firmenrichtlinien nutzen | Nein | Ja |
| Support-Stil trainieren | Ja | Teilweise |
| PDFs durchsuchbar machen | Nein | Ja |
| Feste Extraktionsstruktur lernen | Ja | Teilweise |
| Wissenschatbot mit Quellen bauen | Nein | Ja |
| Antwortformat standardisieren | Ja | Teilweise |
| Häufig wechselnde Produktdaten nutzen | Nein | Ja |
Für wen lohnt sich Fine-Tuning?
Fine-Tuning lohnt sich nicht für jedes Projekt. Der Aufwand sollte immer im Verhältnis zum Nutzen stehen.
Besonders sinnvoll für
Unternehmen mit klaren Spezialaufgaben
Wenn immer wieder ähnliche Aufgaben in hoher Stückzahl anfallen, kann Fine-Tuning sehr wertvoll sein.
Teams mit guter Datenbasis
Wenn hochwertige Trainingsdaten vorhanden sind, steigen die Erfolgschancen deutlich.
Anwendungen mit festen Antwortmustern
Zum Beispiel Extraktion, Klassifikation, Markenton oder strukturierte Ausgabe.
Projekte mit hoher Wiederholbarkeit
Wenn dieselbe Art von Eingabe ständig vorkommt, kann sich die Investition eher lohnen.
Weniger sinnvoll für
Kleine Projekte ohne saubere Daten
Dann ist Fine-Tuning oft zu früh.
Wissenssysteme mit vielen aktuellen Dokumenten
Hier ist RAG meist flexibler und kosteneffizienter.
Teams ohne Evaluierungskapazität
Fine-Tuning ohne sauberes Testen ist riskant.
Einfache Content-Projekte
Hier reichen oft gute Prompts, Vorlagen und Retrieval-Ansätze.
Für wen lohnt sich Fine-Tuning typischerweise?
| Zielgruppe | Einschätzung |
|---|---|
| Einsteiger mit kleiner Wissensseite | Meist noch nicht nötig |
| Unternehmen mit festen Support-Workflows | Oft interessant |
| Teams mit strukturierter Datenextraktion | Sehr interessant |
| Projekte mit wechselndem Fachwissen | Eher RAG zuerst |
| Marken mit starkem Stilanspruch | Kann sinnvoll sein |
| Wissenschatbots für Dokumente | Meist RAG zuerst |
Fine-Tuning für Content- und Wissenswebseiten
Für eine KI-Ratgeber-Webseite ist Fine-Tuning als Thema extrem wichtig, aber als direkte technische Maßnahme oft nicht der erste Schritt.
Warum? Weil Wissensseiten meistens vor allem diese Ziele haben:
- Inhalte gut strukturieren
- Themen verständlich erklären
- Suchintentionen bedienen
- internes Wissen vernetzen
- semantische Suche ermöglichen
- Leserfragen beantworten
Dafür sind oft bessere Inhalte, gute Informationsarchitektur, RAG, semantische Suche und interne Verlinkung zunächst wichtiger als echtes Fine-Tuning.
Wenn du später aber einen KI-Assistenten für deine Wissensseite bauen willst, könnte Fine-Tuning dann sinnvoll werden, wenn du dem Assistenten einen ganz bestimmten didaktischen Stil oder eine feste Antwortstruktur geben möchtest.
Was ist oft die bessere Reihenfolge in echten Projekten?
Viele erfolgreiche Projekte gehen nicht sofort ins Fine-Tuning, sondern arbeiten in Stufen.
Sinnvolle Reihenfolge
- Problem klar definieren
- Gute Prompts testen
- Daten sauber strukturieren
- RAG oder Retrieval aufbauen
- Ergebnisse evaluieren
- Erst danach prüfen, ob Fine-Tuning noch nötig ist
Das spart oft Geld, Zeit und Fehlentscheidungen.
Fine-Tuning ist keine Abkürzung für schlechte Datenarbeit
Das ist einer der wichtigsten Praxissätze überhaupt.
Wenn dein System schlechte Dokumente, unklare Daten, inkonsistente Ausgaben oder fehlende Strukturen hat, dann wird Fine-Tuning das selten elegant lösen. Häufig verschiebt es das Problem nur.
Fine-Tuning ist am stärksten, wenn die Grundlagen bereits sauber sind.
Zusammenfassung: Wann Fine-Tuning sinnvoll ist und wann RAG besser passt
Fine-Tuning ist die gezielte Anpassung eines vortrainierten KI-Modells für spezielle Aufgaben, Formate, Stile oder Domänen. Es verändert das Verhalten des Modells und kann die Leistung in eng umrissenen Aufgaben deutlich verbessern.
RAG dagegen verändert das Modell nicht direkt, sondern gibt ihm bei der Anfrage passende externe Informationen aus Dokumenten oder Wissensquellen. Deshalb ist RAG oft die bessere Lösung, wenn aktuelle, interne oder häufig wechselnde Inhalte genutzt werden sollen.
Die wichtigste Unterscheidung lautet deshalb:
- Fine-Tuning für Verhalten
- RAG für Wissen
In vielen professionellen Anwendungen werden beide Ansätze kombiniert. Genau darin liegt oft die beste Lösung: ein Modell, das sich passend verhält und zugleich auf aktuelle, nachvollziehbare Wissensquellen zugreifen kann.
Die wichtigsten Punkte auf einen Blick
| Kernpunkt | Bedeutung |
|---|---|
| Fine-Tuning ist Nachtraining | Ein bestehendes Modell wird für spezielle Zwecke angepasst |
| Es verändert das Modellverhalten | Stil, Struktur, Format und Spezialaufgaben können verbessert werden |
| Es ersetzt keine Wissensdatenbank | Für Dokumente und aktuelle Inhalte ist Fine-Tuning oft nicht ideal |
| RAG liefert Wissen zur Laufzeit | Externe Inhalte werden bei Bedarf abgerufen |
| Fine-Tuning und RAG sind keine Gegner | Sie lösen unterschiedliche Probleme |
| Datenqualität entscheidet | Schlechte Trainingsdaten verschlechtern die Ergebnisse |
| Nicht jedes Projekt braucht Fine-Tuning | Oft sind Prompting und RAG zuerst sinnvoller |
FAQ zu Fine-Tuning einfach erklärt
Was ist Fine-Tuning in einfachen Worten?
Fine-Tuning ist das gezielte Nachtrainieren eines bereits vorhandenen KI-Modells, damit es bei bestimmten Aufgaben, in einer bestimmten Fachsprache oder in einem gewünschten Stil besser funktioniert.
Was ist der Unterschied zwischen Pretraining und Fine-Tuning?
Pretraining ist das große Grundtraining eines Modells auf riesigen Datenmengen. Fine-Tuning kommt danach und spezialisiert das Modell für einen engeren Anwendungsfall.
Wann sollte man Fine-Tuning nutzen?
Fine-Tuning ist besonders dann sinnvoll, wenn ein Modell in einer bestimmten Aufgabe, einem festen Antwortformat, einer Fachdomäne oder einer klaren Markenstimme konsistenter werden soll.
Wann ist RAG besser als Fine-Tuning?
RAG ist meist besser, wenn das Modell mit aktuellen, internen oder häufig wechselnden Dokumenten arbeiten soll. Es eignet sich besonders für Wissenssysteme, FAQ-Chatbots und Dokumentensuche.
Kann Fine-Tuning aktuelles Wissen zuverlässig speichern?
Nur sehr begrenzt. Fine-Tuning ist keine ideale Lösung für laufend aktualisierte Informationen. Für solche Inhalte ist RAG meist flexibler und besser kontrollierbar.
Ist Fine-Tuning teuer?
Es kann teuer werden, vor allem durch Datenaufbereitung, Qualitätskontrolle, Testen und Wartung. Nicht nur die Rechenleistung kostet, sondern vor allem die saubere Vorbereitung der Trainingsdaten.
Kann man Fine-Tuning und RAG kombinieren?
Ja. Das ist sogar oft die stärkste Lösung. Fine-Tuning kann das Verhalten und den Stil verbessern, während RAG aktuelles Wissen und nachvollziehbare Quellen bereitstellt.
Lohnt sich Fine-Tuning für kleine Webseiten?
In vielen Fällen noch nicht. Für kleine Wissens- oder Content-Webseiten reichen oft gute Inhalte, klare Struktur, gutes Prompting und später ein RAG-System deutlich eher aus.