Embeddings einfach erklärt: Die unsichtbare Sprache moderner KI verstehen
Embeddings gehören zu den wichtigsten Grundlagen moderner Künstlicher Intelligenz. Ohne sie würden viele heutige KI-Anwendungen deutlich schlechter funktionieren oder gar nicht erst möglich sein. Wer verstehen will, wie Suchmaschinen, Chatbots, Empfehlungssysteme, RAG-Systeme oder Vektor-Datenbanken arbeiten, kommt an Embeddings nicht vorbei.
Das Problem ist nur: Der Begriff klingt technisch und abstrakt. Viele Einsteiger lesen Sätze wie „Texte werden in numerische Vektoren umgewandelt“ und steigen an genau diesem Punkt aus. Dabei ist die Grundidee eigentlich sehr logisch.
In diesem Beitrag lernst du Embeddings von Grund auf. Du brauchst kein Vorwissen in Mathematik, Informatik oder Machine Learning. Wir gehen Schritt für Schritt vor: erst das Grundprinzip, dann die Technik, dann konkrete Beispiele aus der Praxis. Am Ende wirst du verstehen, warum Embeddings für moderne KI so zentral sind, wie sie funktionieren und wann sie eingesetzt werden.
Was sind Embeddings?
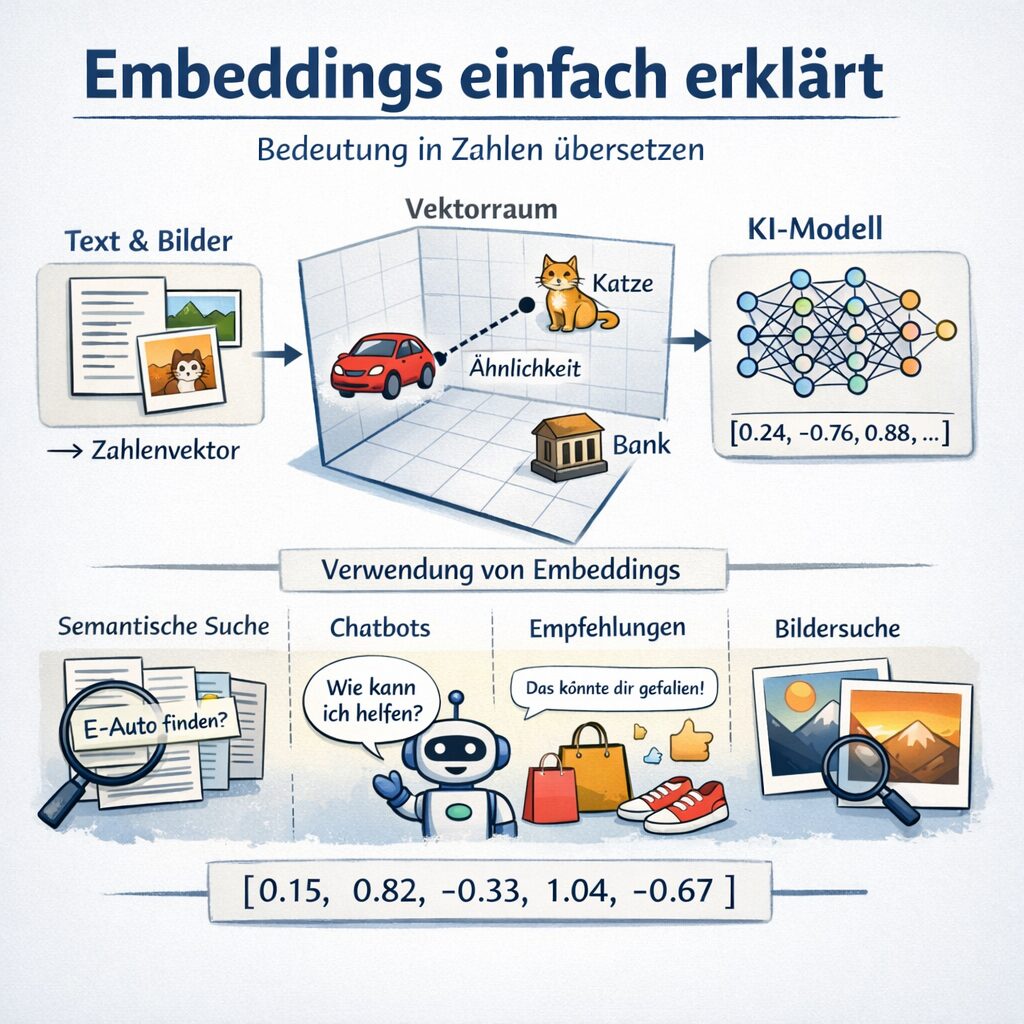
Embeddings sind eine numerische Darstellung von Informationen. Das klingt zunächst trocken, ist aber im Kern einfach: Ein Computer kann mit menschlicher Sprache, Bildern oder Bedeutungen nicht direkt umgehen. Maschinen rechnen mit Zahlen. Deshalb müssen Inhalte so übersetzt werden, dass ein Modell sie mathematisch verarbeiten kann.
Genau das leisten Embeddings.
Ein Embedding ist also eine Art Zahlencode, der die Bedeutung eines Inhalts möglichst gut einfängt. Dieser Inhalt kann ein Wort, ein Satz, ein ganzer Text, ein Bild, ein Audioausschnitt oder sogar ein Produkt in einem Shop sein.
Das Besondere daran: Gute Embeddings speichern nicht nur rohe Daten, sondern vor allem Beziehungen und Ähnlichkeiten. Inhalte mit ähnlicher Bedeutung liegen im Embedding-Raum näher beieinander. Inhalte mit unterschiedlicher Bedeutung liegen weiter auseinander.
Einfach gesagt:
- Ein Embedding verwandelt Bedeutung in Zahlen
- ähnliche Inhalte bekommen ähnliche Zahlenmuster
- dadurch kann KI Ähnlichkeiten erkennen, vergleichen und suchen
Warum braucht KI Embeddings?
Menschen verstehen Sprache intuitiv. Wenn wir die Wörter „Auto“, „Fahrzeug“ und „Wagen“ lesen, erkennen wir sofort, dass diese Begriffe eng zusammenhängen. Ein Computer sieht zunächst aber nur Zeichenfolgen.
Für eine Maschine sind diese Begriffe ohne weitere Verarbeitung nur Textstücke:
- Auto
- Fahrzeug
- Wagen
Ohne Embeddings erkennt ein klassisches System oft nur exakte Treffer. Sucht jemand nach „rotes Fahrzeug“, findet ein einfaches Suchsystem vielleicht keinen Text mit „rotes Auto“, obwohl beide inhaltlich fast gleich sind.
Embeddings lösen genau dieses Problem. Sie helfen Maschinen, nicht nur Zeichen, sondern Bedeutungen zu vergleichen.
Dadurch werden viele KI-Funktionen überhaupt erst möglich:
- semantische Suche
- intelligente Chatbots
- Dokumentensuche in großen Wissensdatenbanken
- Produktempfehlungen
- Clustering und Gruppierung ähnlicher Inhalte
- RAG-Systeme mit relevanten Kontexttreffern
- Ähnlichkeitssuche in Bildern oder Texten
Die Grundidee hinter Embeddings
Stell dir vor, jedes Wort, jeder Satz oder jedes Dokument bekommt einen Platz in einem riesigen unsichtbaren Raum. Dieser Raum hat nicht nur zwei oder drei Dimensionen wie eine normale Karte, sondern oft Hunderte oder Tausende Dimensionen.
In diesem Raum gilt:
- Begriffe mit ähnlicher Bedeutung liegen näher zusammen
- Begriffe mit anderer Bedeutung liegen weiter entfernt
- Beziehungen zwischen Begriffen lassen sich mathematisch messen
Das ist die Kernidee von Embeddings.
Ein einfaches Alltagsbeispiel
Denke an eine Bibliothek ohne alphabetische Ordnung. Stattdessen werden Bücher nach inhaltlicher Nähe ins Regal gestellt. Bücher über Katzen, Haustiere und Tierpflege stehen nahe beieinander. Bücher über Autos oder Börsen weiter entfernt.
Genauso funktionieren Embeddings:
- ähnliche Inhalte landen in ähnlichen Bereichen
- unähnliche Inhalte in anderen Bereichen
- die Maschine kann dadurch „Nachbarn“ mit ähnlicher Bedeutung finden
Embeddings in einem Satz erklärt
Embeddings sind Zahlenvektoren, die die Bedeutung von Inhalten so abbilden, dass ähnliche Inhalte im mathematischen Raum nah beieinander liegen.
Was ist ein Vektor?
Wer Embeddings verstehen will, muss kurz das Wort „Vektor“ verstehen. Keine Sorge: Dafür brauchst du keine komplizierte Mathematik.
Ein Vektor ist einfach eine Liste von Zahlen.
Zum Beispiel:
[0.12, -0.45, 0.88, 0.03, -0.21]
Ein echtes Embedding ist oft viel länger, etwa 384, 768, 1024 oder mehr Zahlenwerte. Jede Zahl trägt einen kleinen Teil zur Gesamtbedeutung bei. Für Menschen ist diese Liste nicht direkt lesbar. Für Maschinen ist sie perfekt.
Man kann sich einen Vektor wie ein Koordinatensystem vorstellen. Jede Zahl gibt an, wo sich ein Inhalt im Bedeutungsraum befindet.
Was wird überhaupt eingebettet?
Embeddings lassen sich auf viele Datentypen anwenden. Am häufigsten geht es um Text, aber nicht nur.
| Datentyp | Beispiel | Zweck |
|---|---|---|
| Wörter | „Hund“, „Auto“, „Bank“ | Wortbedeutung erfassen |
| Sätze | „Der Hund schläft im Garten“ | Satzbedeutung vergleichen |
| Dokumente | Blogartikel, Verträge, PDFs | semantische Suche, RAG |
| Bilder | Produktfoto, Gesicht, Landschaft | Bildähnlichkeit, Bildsuche |
| Audio | Sprachaufnahmen, Musik | Audiovergleich, Erkennung |
| Produkte | Schuhe, Bücher, Gadgets | Empfehlungen, Ähnlichkeit |
| Nutzerprofile | Interessen, Klickverhalten | Personalisierung |
Wie entstehen Embeddings?
Embeddings werden von Modellen erzeugt. Diese Modelle wurden auf sehr großen Datenmengen trainiert und lernen dabei, Muster, Zusammenhänge und Bedeutungsnähe zu erkennen.
Vereinfacht läuft das so ab:
1. Das Modell bekommt Eingabedaten
Zum Beispiel einen Satz wie:
„Der Kunde sucht ein günstiges Elektroauto.“
2. Das Modell analysiert Muster und Kontext
Es betrachtet nicht nur einzelne Wörter, sondern auch den Zusammenhang. Es erkennt, dass „günstig“ eine Preisangabe ist, „Elektroauto“ ein Fahrzeugtyp und „sucht“ auf eine Suchabsicht hinweist.
3. Das Modell erzeugt einen Zahlenvektor
Am Ende entsteht ein Embedding, also eine Zahlenliste, die diese Gesamtbedeutung repräsentiert.
4. Dieser Vektor kann verglichen werden
Nun kann das System messen, welche anderen Texte oder Inhalte ähnliche Embeddings haben.
So findet es zum Beispiel:
- „preiswertes E-Auto“
- „bezahlbares elektrisches Fahrzeug“
- „billiger Stromer“
Obwohl die Formulierungen unterschiedlich sind, können gute Embeddings erkennen, dass die Bedeutung ähnlich ist.
Warum sind Embeddings so mächtig?
Der große Vorteil von Embeddings liegt darin, dass sie nicht nur exakte Wörter vergleichen, sondern semantische Nähe.
Das ist ein riesiger Unterschied zu älteren Such- oder Analyseverfahren.
Klassische Suche
Eine klassische Suche schaut oft darauf, ob ein Wort exakt vorkommt. Sie ist stark bei eindeutigen Begriffen, aber schwächer bei Synonymen, Umschreibungen oder natürlicher Sprache.
Embedding-basierte Suche
Eine semantische Suche mit Embeddings erkennt auch verwandte Inhalte. Das System versteht besser, was gemeint ist, nicht nur, was genau geschrieben wurde.
Klassische Suche vs. Embeddings
| Kriterium | Klassische Stichwortsuche | Embedding-basierte Suche |
|---|---|---|
| Grundlage | exakte Wörter | Bedeutung und Ähnlichkeit |
| Synonyme erkennen | meist schlecht | meist gut |
| Umgang mit natürlicher Sprache | begrenzt | deutlich besser |
| Trefferqualität bei langen Fragen | oft schwächer | oft stärker |
| Kontextverständnis | gering | höher |
| Einsatz in RAG | ungeeignet allein | zentral |
Ein praktisches Beispiel
Angenommen, ein Nutzer fragt:
„Wie kann ich meine Stromrechnung senken?“
In deiner Wissensdatenbank gibt es aber nur einen Artikel mit dem Titel:
„Tipps zum Energiesparen im Haushalt“
Eine einfache Stichwortsuche könnte hier scheitern, weil das Wort „Stromrechnung“ nicht vorkommt. Embeddings erkennen dagegen oft, dass beide Inhalte thematisch eng zusammengehören.
Genau deshalb sind Embeddings für moderne Wissenssysteme so wichtig.
Wo werden Embeddings eingesetzt?
Embeddings sind heute in sehr vielen KI-Anwendungen integriert. Oft arbeiten sie im Hintergrund, ohne dass Nutzer den Begriff überhaupt kennen.
Semantische Suche
Statt nur Stichwörter zu vergleichen, sucht das System nach inhaltlich ähnlichen Ergebnissen. Das verbessert Suchfunktionen auf Websites, in Dokumentenarchiven, Shops oder Wissensportalen.
RAG-Systeme
Bei Retrieval-Augmented Generation werden Nutzerfragen in Embeddings umgewandelt. Dann sucht das System passende Textstellen in einer Wissensbasis und gibt diese an ein Sprachmodell weiter. So kann die KI relevanter und faktennäher antworten.
Empfehlungssysteme
Streaming-Dienste, Shops oder Plattformen können Inhalte empfehlen, die inhaltlich ähnlich zu dem sind, was ein Nutzer bereits angesehen oder gekauft hat.
Clustering
Texte oder Produkte können automatisch gruppiert werden. So lassen sich große Datenmengen ordnen, auch wenn keine manuelle Kategorisierung vorliegt.
Dublettenerkennung
Embeddings helfen dabei, sehr ähnliche Inhalte zu finden, zum Beispiel doppelte Artikel, ähnliche Produktbeschreibungen oder fast identische Support-Anfragen.
Bildsuche und Multimodalität
Auch Bilder können als Embeddings dargestellt werden. Dadurch lässt sich nach ähnlichen Bildern suchen oder Text und Bild gemeinsam in einem Modellraum vergleichen.
Typische Einsatzbereiche von Embeddings
| Bereich | Beispiel |
|---|---|
| Chatbots | relevante Wissensabschnitte finden |
| Unternehmenssuche | Verträge, Mails, PDFs semantisch durchsuchen |
| E-Commerce | ähnliche Produkte empfehlen |
| SEO und Content | thematisch verwandte Inhalte erkennen |
| Support | ähnliche Kundenanfragen finden |
| Social Media | Beiträge clustern und Trends erkennen |
| Bildanalyse | ähnliche Bilder oder Motive finden |
| Forschung | Dokumente nach Themen gruppieren |
Wie misst man Ähnlichkeit zwischen Embeddings?
Wenn Inhalte als Zahlenvektoren vorliegen, kann man ihre Ähnlichkeit mathematisch messen. Dafür gibt es verschiedene Verfahren. Das bekannteste im Embedding-Bereich ist die sogenannte Kosinus-Ähnlichkeit.
Der Name klingt kompliziert, aber die Idee ist überschaubar: Man prüft, wie ähnlich die Richtung zweier Vektoren ist.
Vereinfacht gesagt
- sehr ähnliche Inhalte → hohe Ähnlichkeit
- teilweise ähnliche Inhalte → mittlere Ähnlichkeit
- stark unterschiedliche Inhalte → niedrige Ähnlichkeit
Das System braucht also keine perfekte Wortgleichheit. Es schaut darauf, wie nah die Inhalte im Bedeutungsraum liegen.
Warum kann ein Embedding nicht einfach von Menschen gelesen werden?
Viele Einsteiger fragen sich: Wenn ein Embedding Bedeutung enthält, warum kann ich dann nicht einfach an den Zahlen erkennen, was gemeint ist?
Die Antwort: Weil Bedeutung auf viele Dimensionen verteilt ist. Ein einzelner Zahlenwert steht meist nicht einfach für etwas wie „Tier“, „Preis“ oder „Technik“. Stattdessen entsteht die Bedeutung aus dem Zusammenspiel vieler Werte.
Das ist ähnlich wie bei Musik. Ein einzelner Ton erklärt noch kein Lied. Erst die Kombination vieler Töne erzeugt eine erkennbare Struktur. Bei Embeddings ist es genauso: Erst das Zusammenspiel vieler Zahlen bildet den semantischen Fingerabdruck.
Sind Embeddings und Token dasselbe?
Nein. Diese Begriffe werden oft verwechselt.
Ein Token ist eine kleinere Verarbeitungseinheit für Text. Das kann ein ganzes Wort, ein Wortteil oder ein Satzzeichen sein. Sprachmodelle zerlegen Texte in Tokens, um sie zu verarbeiten.
Ein Embedding ist dagegen die numerische Repräsentation eines Inhalts oder einer Einheit.
Kurz gesagt
- Tokens sind Bausteine der Eingabe
- Embeddings sind Zahlenrepräsentationen mit Bedeutung
Token vs. Embedding
| Begriff | Bedeutung |
|---|---|
| Token | kleinste Verarbeitungseinheit eines Modells |
| Embedding | numerischer Bedeutungsvektor |
| Beispiel Token | „Auto“, „fahr“, „##en“ |
| Beispiel Embedding | Liste aus vielen Zahlenwerten |
Wort-Embeddings, Satz-Embeddings und Dokument-Embeddings
Nicht jedes Embedding arbeitet auf derselben Ebene. Es gibt unterschiedliche Arten, je nachdem, was dargestellt werden soll.
Wort-Embeddings
Früher wurden oft einzelne Wörter als Embeddings dargestellt. Bekannte Verfahren waren Word2Vec oder GloVe. Diese Modelle halfen, semantische Beziehungen zwischen Wörtern zu erfassen.
Das Problem: Ein einzelnes Wort kann je nach Kontext verschiedene Bedeutungen haben.
Beispiel:
- „Bank“ als Geldinstitut
- „Bank“ als Sitzgelegenheit
Ältere Wort-Embeddings hatten oft Schwierigkeiten mit solchen Mehrdeutigkeiten.
Kontextuelle Embeddings
Moderne Modelle berücksichtigen den Kontext. Das Wort „Bank“ erhält je nach Satzumgebung eine andere Repräsentation.
Beispiel:
- „Ich gehe zur Bank, um Geld abzuheben.“
- „Ich sitze auf der Bank im Park.“
Das ist ein großer Fortschritt moderner Transformer-Modelle.
Satz-Embeddings
Hier wird nicht nur ein einzelnes Wort, sondern die Gesamtbedeutung eines Satzes kodiert. Das ist besonders nützlich für semantische Suche und RAG.
Dokument-Embeddings
Auch ganze Absätze, Seiten oder Dokumente können als Embeddings dargestellt werden. Das ist wichtig, wenn große Wissensmengen durchsucht werden sollen.
Die Entwicklung von Embeddings
| Phase | Typische Verfahren | Merkmal |
|---|---|---|
| Frühe Phase | Bag of Words, TF-IDF | zählt Begriffe, versteht aber kaum Bedeutung |
| Wort-Embeddings | Word2Vec, GloVe | Wörter mit semantischer Nähe |
| Kontextuelle Phase | ELMo, BERT | Bedeutung abhängig vom Kontext |
| Moderne Systeme | Transformer-Embeddings | starke Semantik für Sätze, Dokumente, multimodale Daten |
Embeddings und Transformer
Embeddings sind eng mit Transformer-Modellen verbunden. Wenn du bereits etwas über LLMs oder Transformer gelesen hast, ist das der nächste logische Baustein.
Transformer arbeiten nicht direkt mit rohem Text. Die Eingaben müssen zunächst in numerische Formen übersetzt werden. Genau hier kommen Embeddings ins Spiel.
Ein Transformer nutzt Embeddings, um Tokens in Vektoren zu verwandeln. Diese werden dann weiterverarbeitet. Während dieses Prozesses lernt das Modell Beziehungen, Kontext und Bedeutungen.
Das heißt:
- Embeddings sind oft der Einstieg in die Modellverarbeitung
- zugleich können spezialisierte Embedding-Modelle auch separat genutzt werden
- in Such- und RAG-Systemen werden oft eigene Embedding-Modelle eingesetzt
Embeddings in RAG-Systemen verstehen
RAG steht für Retrieval-Augmented Generation. Dabei kombiniert man Sprachmodelle mit externer Wissenssuche. Embeddings spielen dabei eine Schlüsselrolle.
Der Ablauf sieht meist so aus:
1. Inhalte werden in kleine Abschnitte zerlegt
Zum Beispiel Blogbeiträge, PDFs oder Support-Dokumente.
2. Jeder Abschnitt erhält ein Embedding
Damit bekommt jeder Textblock einen Platz im semantischen Raum.
3. Die Nutzerfrage wird ebenfalls in ein Embedding umgewandelt
Nun kann man die Frage mit allen gespeicherten Textabschnitten vergleichen.
4. Die ähnlichsten Treffer werden gefunden
Das System sucht die am besten passenden Dokument- oder Abschnitts-Embeddings.
5. Diese Treffer werden dem Sprachmodell als Kontext gegeben
Erst dadurch kann das Modell gezielt auf die relevante Wissensgrundlage zugreifen.
Ohne Embeddings würde RAG deutlich schlechter funktionieren.
Warum Embeddings für RAG so wichtig sind
| Aufgabe im RAG-System | Rolle von Embeddings |
|---|---|
| Dokumente speichern | als numerische Vektoren ablegen |
| Fragen verstehen | Frage semantisch einordnen |
| Ähnliche Inhalte finden | relevante Chunks suchen |
| Kontext bereitstellen | passende Treffer an das LLM übergeben |
| Antwortqualität erhöhen | weniger Halluzinationen, mehr Relevanz |
Embeddings und Vektor-Datenbanken
Sobald viele Embeddings gespeichert werden, braucht man eine effiziente Möglichkeit, diese zu durchsuchen. Dafür werden oft Vektor-Datenbanken eingesetzt.
Eine Vektor-Datenbank ist speziell dafür gebaut, große Mengen von Embeddings zu speichern und schnell die ähnlichsten Vektoren zu finden.
Das ist wichtig, weil ein Unternehmen schnell Millionen Embeddings haben kann:
- Support-Tickets
- Produktdaten
- Wissensartikel
- PDF-Inhalte
- E-Mails
- Bilder
- Chatverläufe
Normale relationale Datenbanken sind dafür oft nicht optimal. Vektor-Datenbanken sind auf Ähnlichkeitssuche spezialisiert.
Embeddings vs. klassische Keywords
Ein häufiger Irrtum ist: Embeddings ersetzen Keywords komplett. Das stimmt nicht. In der Praxis werden oft beide Ansätze kombiniert.
Keywords sind stark, wenn ein Nutzer ganz konkrete Begriffe verwendet, etwa Produktnummern, Namen, exakte Marken oder technische Codes.
Embeddings sind stark, wenn es um Bedeutung, Synonyme, Umschreibungen und natürliche Sprache geht.
Die beste Lösung ist oft hybrid:
- klassische Suche für exakte Treffer
- Embeddings für semantische Relevanz
Wann Embeddings besonders stark sind
| Situation | Warum Embeddings helfen |
|---|---|
| Nutzer formuliert ungenau | Bedeutung wird trotzdem erkannt |
| Synonyme kommen vor | semantische Nähe statt Wortgleichheit |
| lange natürliche Fragen | besseres Kontextverständnis |
| große Wissensmengen | intelligente Suche nach Relevanz |
| ähnliche Inhalte finden | Nähe im Vektorraum messbar |
Was sind die Grenzen von Embeddings?
So nützlich Embeddings auch sind: Sie sind kein Wundermittel. Wer mit KI arbeitet, sollte auch ihre Grenzen kennen.
Bedeutungsverlust bei schlechter Segmentierung
Wenn Dokumente schlecht in Abschnitte zerlegt werden, kann wichtige Information verloren gehen. Ein zu kurzer Chunk enthält vielleicht zu wenig Kontext. Ein zu langer Chunk ist unscharf.
Modellqualität variiert
Nicht jedes Embedding-Modell ist gleich gut. Manche Modelle sind besser für allgemeine Sprache, andere besser für Code, Wissenschaft, Recht oder Mehrsprachigkeit.
Fachsprache kann schwierig sein
Spezialbegriffe aus Medizin, Recht, Technik oder Finanzen werden nicht von jedem Modell gleich gut abgebildet.
Sprachmischung kann Probleme machen
Einige Modelle funktionieren sehr gut in Englisch, aber schwächer in Deutsch oder in gemischten Datensätzen.
Ähnlich bedeutet nicht immer korrekt
Nur weil zwei Inhalte semantisch nah sind, heißt das nicht automatisch, dass der Treffer auch sachlich präzise genug ist.
Häufige Fehler im Umgang mit Embeddings
| Fehler | Problem |
|---|---|
| falsches Embedding-Modell | schlechte Trefferqualität |
| zu große Textblöcke | ungenaue semantische Suche |
| zu kleine Textblöcke | fehlender Kontext |
| nur Embeddings, keine Filter | irrelevante Treffer können mitkommen |
| kein Re-Ranking | gute Trefferreihenfolge fehlt |
| Sprachmodell und Embeddings schlecht kombiniert | RAG wirkt unpräzise |
Embeddings sind keine Magie
Wichtig ist: Embeddings „verstehen“ Inhalte nicht wie Menschen. Sie berechnen Muster und Beziehungen auf Basis von Trainingsdaten. Das Ergebnis kann beeindruckend gut sein, aber es ist kein menschliches Verstehen im eigentlichen Sinn.
Trotzdem reicht diese mathematische Annäherung in vielen Fällen aus, um sehr nützliche KI-Systeme zu bauen.
Ein anschauliches Beispiel aus dem Alltag
Stell dir vor, du betreibst eine KI-Ratgeber-Webseite. Ein Leser gibt die Frage ein:
„Wie speichert KI Bedeutung in Zahlen?“
In deiner Datenbank steht aber ein Abschnitt mit:
„Embeddings übersetzen Texte in numerische Vektoren, damit Maschinen semantische Ähnlichkeiten berechnen können.“
Die exakten Wörter sind unterschiedlich. Das Thema ist aber klar dasselbe. Ein gutes Embedding-System erkennt diese Nähe und liefert den richtigen Abschnitt.
Das ist der eigentliche Nutzen: Es findet nicht nur gleiche Wörter, sondern ähnliche Gedanken.
Embeddings in der Praxis eines Webseitenbetreibers
Für eine Wissensseite, einen Blog oder ein digitales Produkt können Embeddings besonders interessant sein.
Interne KI-Suche
Statt nur nach exakten Begriffen zu suchen, können Besucher Fragen in natürlicher Sprache stellen und passende Inhalte finden.
Wissensdatenbank für Chatbots
Ein Website-Chatbot kann mit Embeddings passende Artikel oder Absätze aus deiner Wissensbasis ziehen.
Ähnliche Artikel anzeigen
Ein System kann erkennen, welche Beiträge thematisch nah beieinander liegen und automatisch Empfehlungen ausspielen.
Content-Clustering
Wenn du viele Artikel veröffentlichst, lassen sich ähnliche Themenfelder besser gruppieren. Das hilft bei interner Struktur, Navigation und Ausbau von Themenclustern.
Vorteile von Embeddings für Wissenswebseiten
| Nutzen | Erklärung |
|---|---|
| bessere interne Suche | Nutzer finden schneller relevante Inhalte |
| smarter FAQ-Chatbot | Antworten basieren auf echter Wissensbasis |
| stärkere Content-Struktur | Themen lassen sich sinnvoll clustern |
| bessere User Experience | weniger Frust bei Suchanfragen |
| mehr Relevanz | Inhalte werden semantisch verknüpft |
Muss man Embeddings selbst trainieren?
In vielen Fällen: nein.
Heute gibt es viele fertige Embedding-Modelle, die bereits sehr gut funktionieren. Für viele Anwendungen reicht es, ein passendes Modell auszuwählen und zu nutzen.
Eigene Trainings oder Anpassungen werden eher dann interessant, wenn:
- sehr spezielle Fachsprache verwendet wird
- hohe Präzision in einem engen Bereich nötig ist
- eigene Datendomänen stark vom Standard abweichen
Für die meisten Projekte ist die Auswahl des richtigen Modells, die gute Chunking-Strategie und die saubere Datenstruktur wichtiger als eigenes Training.
Embeddings und Mehrsprachigkeit
Viele moderne Embedding-Modelle können mehrere Sprachen verarbeiten. Das ist besonders nützlich, wenn Inhalte auf Deutsch, Englisch oder anderen Sprachen durchsucht werden sollen.
Aber Vorsicht: Nicht jedes Modell ist in jeder Sprache gleich stark. Wer mit deutschsprachigen Inhalten arbeitet, sollte testen, wie gut das gewählte Modell deutsche Suchanfragen und Dokumente tatsächlich abbildet.
Gerade für europäische Websites, internationale Wissensdatenbanken oder mehrsprachige Supportsysteme ist das ein wichtiger Punkt.
Wie wählt man ein gutes Embedding-Modell aus?
Bei der Auswahl kommt es auf den Einsatzzweck an.
Wichtige Fragen
- Soll das Modell eher kurze Sätze oder lange Dokumente einbetten?
- Arbeitet das System auf Deutsch, Englisch oder mehrsprachig?
- Geht es um allgemeine Sprache oder Fachsprache?
- Ist Geschwindigkeit wichtiger oder maximale Genauigkeit?
- Wie groß dürfen die Vektoren sein?
- Welche Infrastruktur steht zur Verfügung?
Auswahlkriterien für Embedding-Modelle
| Kriterium | Warum es wichtig ist |
|---|---|
| Sprachunterstützung | Modell muss die Zielsprache gut beherrschen |
| Domänenpassung | Fachtexte brauchen oft spezialisierte Modelle |
| Vektorgröße | beeinflusst Speicherbedarf und Performance |
| Geschwindigkeit | wichtig für Live-Suche und Chatbots |
| Genauigkeit | bestimmt Trefferqualität |
| Lizenz und Kosten | relevant für kommerzielle Nutzung |
Embeddings und Speicherbedarf
Ein Embedding besteht aus vielen Zahlen. Wenn du tausende oder Millionen Texte speicherst, wächst der Speicherbedarf schnell an. Deshalb spielen auch technische Entscheidungen eine Rolle:
- Wie groß ist der Vektor?
- Wie viele Dokumente gibt es?
- Werden nur Texte oder auch Bilder eingebettet?
- Wie oft wird neu indexiert?
Das ist einer der Gründe, warum Vektor-Datenbanken und effiziente Suchverfahren so wichtig sind.
Sind Embeddings immer gleich?
Nicht unbedingt. Dasselbe Wort oder derselbe Satz kann je nach Modell unterschiedlich eingebettet werden. Unterschiedliche Modelle lernen unterschiedliche Darstellungen. Auch die Dimensionalität kann variieren.
Deshalb ist ein Embedding nie einfach „die eine wahre Bedeutung“, sondern immer die modellabhängige numerische Darstellung eines Inhalts.
Ein ganz einfaches Merkschema
Wenn du dir nur drei Dinge merken willst, dann diese:
1. Embeddings übersetzen Bedeutung in Zahlen
Damit Maschinen Inhalte rechnerisch vergleichen können.
2. Ähnliche Inhalte liegen im Vektorraum näher zusammen
Deshalb funktionieren semantische Suche und RAG.
3. Embeddings sind ein Fundament moderner KI-Systeme
Ohne sie wären viele intelligente Such-, Analyse- und Empfehlungssysteme deutlich schlechter.
Embeddings für Einsteiger: Das wichtigste Verständnis
Viele Anfänger glauben, Embeddings seien eine Nebentechnologie. In Wahrheit sind sie eines der Grundelemente moderner KI-Infrastruktur.
Sie verbinden zwei Welten:
- die menschliche Welt aus Sprache, Bedeutung und Kontext
- die maschinelle Welt aus Zahlen, Vektoren und mathematischer Ähnlichkeit
Genau diese Übersetzungsleistung macht sie so wertvoll.
Fazit: Warum du Embeddings verstehen solltest
Embeddings sind kein Modewort, sondern eine Kerntechnologie moderner KI. Sie sorgen dafür, dass Maschinen Inhalte nicht nur als rohe Zeichenketten sehen, sondern als mathematisch vergleichbare Bedeutungsstrukturen.
Wer mit LLMs, RAG, Vektor-Datenbanken, Chatbots, semantischer Suche oder KI-Wissenssystemen arbeitet, sollte Embeddings verstehen. Nicht unbedingt bis ins letzte mathematische Detail, aber so weit, dass klar ist, was sie leisten, wo ihre Stärken liegen und wo ihre Grenzen beginnen.
Für deinen KI-Wissensbereich ist das Thema besonders wertvoll, weil es eine Brücke zwischen Grundlagen und Praxis schlägt. Embeddings erklären, wie moderne Systeme Bedeutung abbilden. Damit bilden sie einen perfekten Baustein zwischen Themen wie LLM, Transformer, RAG und Vektor-Datenbanken.
FAQ: Embeddings einfach erklärt
Was sind Embeddings in der KI?
Embeddings sind numerische Vektoren, die Inhalte wie Wörter, Sätze, Dokumente oder Bilder so darstellen, dass Maschinen deren Bedeutung und Ähnlichkeit mathematisch vergleichen können.
Warum sind Embeddings wichtig?
Embeddings sind wichtig, weil sie semantische Suche, RAG-Systeme, Chatbots, Empfehlungssysteme und viele weitere KI-Anwendungen ermöglichen. Sie helfen Maschinen, ähnliche Inhalte zu erkennen, auch wenn andere Wörter verwendet werden.
Was ist der Unterschied zwischen Embeddings und Tokens?
Tokens sind Verarbeitungseinheiten eines Modells, zum Beispiel Wörter oder Wortteile. Embeddings sind numerische Repräsentationen mit semantischer Bedeutung. Tokens sind also Bausteine, Embeddings deren mathematische Darstellung.
Wofür werden Embeddings in RAG verwendet?
In RAG-Systemen werden Dokumente und Nutzerfragen in Embeddings umgewandelt. Dann sucht das System die semantisch ähnlichsten Inhalte und gibt diese als Kontext an das Sprachmodell weiter.
Können Embeddings auch für Bilder verwendet werden?
Ja. Nicht nur Texte, sondern auch Bilder, Audio und andere Datentypen können als Embeddings dargestellt werden. Dadurch lassen sich ähnliche Bilder oder multimodale Inhalte vergleichen.
Verstehen Embeddings Inhalte wie ein Mensch?
Nein. Embeddings berechnen mathematische Muster und Bedeutungsnähe auf Basis von Trainingsdaten. Das kann sehr leistungsfähig sein, ist aber kein menschliches Verstehen im eigentlichen Sinn.
Braucht man für Embeddings eine Vektor-Datenbank?
Nicht immer, aber bei größeren Datenmengen ist eine Vektor-Datenbank sehr sinnvoll. Sie hilft dabei, viele Embeddings effizient zu speichern und schnell nach ähnlichen Vektoren zu durchsuchen.
Sind Embeddings nur für große Unternehmen relevant?
Nein. Auch kleinere Websites, Wissensportale, Shops oder interne Dokumentensysteme können von Embeddings profitieren, zum Beispiel durch bessere Suche, ähnliche Inhalte oder KI-gestützte Assistenten.