Was ist Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) ist eine Architektur zur Erweiterung von Large Language Models (LLMs) durch externe Wissensquellen.
RAG
Wie funktioniert Retrieval Augmented Generation (RAG)
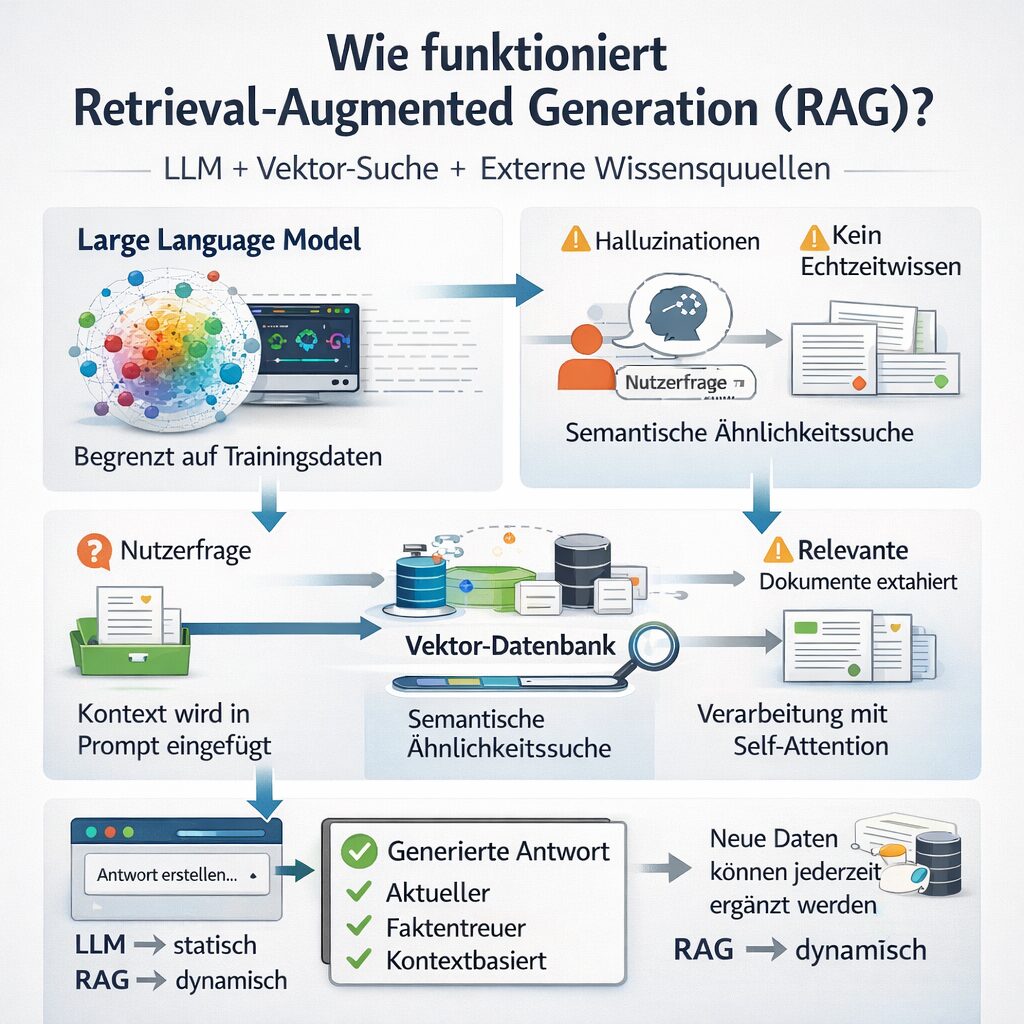
Retrieval-Augmented Generation (RAG) ist eine Architektur zur Erweiterung von Large Language Models (LLMs) durch externe Wissensquellen. Während ein klassisches Large Language Model ausschließlich auf seinem Trainingsdatensatz basiert, kombiniert RAG ein Sprachmodell mit einem Retrieval-System, das relevante Informationen in Echtzeit aus einer Datenbank oder Dokumentensammlung abruft.
RAG löst eines der größten Probleme moderner KI-Systeme: die Begrenzung auf statisches Trainingswissen. Durch die Integration externer Datenquellen ermöglicht Retrieval-Augmented Generation präzisere, aktuellere und faktenbasiertere Antworten.
Warum ist RAG notwendig?
Die Grenzen klassischer Large Language Models
Ein Large Language Model:
- Hat ein festes Trainingsdatum
- Kann keine neuen Informationen „nachladen“
- Neigt zu Halluzinationen
- Arbeitet ausschließlich mit internem Wahrscheinlichkeitswissen
Das bedeutet:
Ein LLM weiß nur das, was es im Training gelernt hat – und selbst das nur statistisch.
Hier setzt Retrieval-Augmented Generation an.
Grundprinzip von RAG
RAG kombiniert zwei Komponenten:
- Retrieval (Informationssuche)
- Generation (Textgenerierung durch ein LLM)
Das System arbeitet in mehreren Schritten:
- Nutzer stellt eine Anfrage
- Ein Suchsystem identifiziert relevante Dokumente
- Diese Dokumente werden als Kontext dem LLM übergeben
- Das LLM generiert eine Antwort basierend auf diesem erweiterten Kontext
RAG = LLM + externer Wissenszugriff
Architektur von Retrieval-Augmented Generation
Komponente 1: Dokumentenspeicher
Eine Datenbasis kann enthalten:
- Unternehmensdokumente
- Wissensdatenbanken
- Produktinformationen
- Finanzberichte
- Juristische Texte
- Medizinische Daten
Diese Daten werden vorab indexiert.
Komponente 2: Vektor-Datenbank
Dokumente werden in sogenannte Embeddings umgewandelt. Diese mathematischen Vektoren repräsentieren semantische Bedeutung.
Vektor-Datenbanken ermöglichen:
- Ähnlichkeitssuche
- Semantische Suche statt Keyword-Suche
- Schnelle Kontextidentifikation
Ohne Vektor-Datenbank funktioniert modernes RAG nicht effizient.
Komponente 3: Retrieval-System
Bei einer Nutzeranfrage wird:
- Die Anfrage ebenfalls in einen Vektor umgewandelt
- Mit gespeicherten Dokument-Vektoren verglichen
- Die relevantesten Inhalte extrahiert
Das Ergebnis ist ein kontextrelevanter Textblock.
Komponente 4: Large Language Model
Das LLM erhält:
- Nutzerfrage
- Extrahierten Kontext
Und generiert darauf basierend eine strukturierte Antwort.
Das LLM „halluziniert“ weniger, da es auf reale Dokumente zurückgreifen kann.
Technischer Ablauf von RAG Schritt für Schritt
1. Datenaufbereitung
Dokumente werden:
- Bereinigt
- In kleinere Textabschnitte zerlegt
- In Embeddings konvertiert
- In einer Vektor-Datenbank gespeichert
2. Query Processin
Die Nutzeranfrage wird:
- Tokenisiert
- In ein Embedding umgewandelt
- Gegen die Datenbank gematcht
3. Kontext-Injektion
Die relevantesten Dokumente werden dem Prompt hinzugefügt.
Beispiel:
„Beantworte die folgende Frage basierend auf dem Kontext:“
Kontext:
[Extrahierter Text]
Frage:
[Nutzeranfrage]
4. Antwortgenerierung
Das LLM erzeugt eine strukturierte, kontextbasierte Antwort.
Unterschied zwischen LLM und RAG
| Klassisches LLM | RAG-System |
|---|---|
| Statisches Wissen | Dynamisches Wissen |
| Halluzination möglich | Höhere Faktentreue |
| Kein Zugriff auf Datenbanken | Externer Datenzugriff |
| Reines Wahrscheinlichkeitsmodell | Hybrid-System |
RAG erweitert ein Large Language Model um eine Wissensinfrastruktur.
Vorteile von Retrieval-Augmented Generation
Aktuelle Informationen
RAG kann auf aktuelle Daten zugreifen – im Gegensatz zu rein trainierten Modellen.
Reduzierte Halluzination
Durch echten Kontext sinkt die Wahrscheinlichkeit erfundener Fakten.
Unternehmensintegration
RAG ermöglicht:
- Interne Wissenssysteme
- KI-gestützte Dokumentensuche
- Support-Automatisierung
- Vertragsanalyse
Skalierbarkeit
Neue Dokumente können einfach ergänzt werden, ohne das gesamte LLM neu zu trainieren.
Grenzen von RAG
Kontextfenster-Beschränkung
Das LLM kann nur eine begrenzte Anzahl Tokens gleichzeitig verarbeiten.
Retrieval-Qualität
Wenn die Suche falsche Dokumente liefert, verschlechtert sich die Antwortqualität.
Datenqualität
Schlechte Datenbasis → schlechte KI-Antwort.
RAG in Unternehmen
Retrieval-Augmented Generation wird eingesetzt für:
- Interne Wissensdatenbanken
- Chatbots im Kundenservice
- Compliance-Analyse
- Finanzdokumente
- Juristische Beratungssysteme
- Medizinische Entscheidungsunterstützung
RAG ist heute einer der wichtigsten Bausteine für produktive KI-Systeme.
Erweiterte Varianten von RAG
Hybrid Retrieval
Kombination aus:
- Keyword-Suche
- Vektor-Suche
Multi-Hop Retrieval
Mehrstufige Suche bei komplexen Fragestellungen.
Agentic RAG
RAG kombiniert mit autonomen KI-Agenten, die selbstständig Datenquellen auswählen.
RAG vs Fine-Tuning
Fine-Tuning:
- Verändert Modellparameter
- Teuer
- Rechenintensiv
RAG:
- Externe Wissensanbindung
- Flexibel
- Schnell aktualisierbar
Für viele Unternehmen ist RAG effizienter als Fine-Tuning.
Zukunft von Retrieval-Augmented Generation
Die Entwicklung geht in Richtung:
- Echtzeit-Datenintegration
- Multimodale RAG-Systeme
- API-basierte Wissensquellen
- On-Premise-Lösungen für sensible Daten
- Kombination mit KI-Agenten
RAG wird zur Infrastruktur-Technologie für unternehmensnahe KI-Systeme.
Fazit: Warum RAG die nächste Evolutionsstufe von LLMs ist
Ein Large Language Model allein ist leistungsfähig – aber statisch.
Retrieval-Augmented Generation macht es dynamisch.
RAG verbindet:
- Sprachintelligenz
- Semantische Suche
- Externe Wissensquellen
- Echtzeit-Integration
Damit entsteht ein hybrides System, das näher an praktischen Unternehmensanforderungen arbeitet als reine generative Modelle.
Für dein „Wissen“-Silo ist RAG die logische Erweiterung nach LLM, da es direkt an die Grundlagen von:
- Embeddings
- Vektor-Datenbanken
- Transformer-Architektur
- Kontextfenster
anschließt.
FAQ – Retrieval-Augmented Generation (RAG)
Was ist Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) ist eine KI-Architektur, die ein Large Language Model (LLM) mit einer externen Wissensquelle kombiniert. Statt nur auf Trainingsdaten zu basieren, ruft RAG relevante Informationen aus einer Datenbank ab und integriert sie in die Antwortgenerierung. Dadurch entstehen präzisere und aktuellere Ergebnisse.
Wie funktioniert RAG?
RAG arbeitet in zwei Schritten: Zuerst durchsucht ein Retrieval-System eine Vektor-Datenbank nach relevanten Dokumenten. Anschließend erhält das Large Language Model diese Informationen als Kontext und generiert darauf basierend eine Antwort. So kombiniert RAG semantische Suche mit Textgenerierung.
Warum ist RAG besser als ein reines LLM?
Ein klassisches LLM arbeitet nur mit seinem Trainingswissen und kann halluzinieren. RAG greift zusätzlich auf externe Datenquellen zu. Dadurch verbessert sich die Faktentreue, Aktualität und Genauigkeit der Antworten erheblich.
Was ist der Unterschied zwischen RAG und Fine-Tuning?
Fine-Tuning verändert die Modellparameter eines LLM und ist rechenintensiv. RAG hingegen ergänzt ein Modell um eine externe Wissensquelle, ohne das Modell neu zu trainieren. RAG ist flexibler und einfacher zu aktualisieren.
Wofür wird RAG eingesetzt?
Retrieval-Augmented Generation wird in Unternehmens-KI, Wissensdatenbanken, Kundenservice-Chatbots, juristischen Analyse-Systemen und Finanzanwendungen eingesetzt. Besonders dort, wo aktuelle oder interne Dokumente verarbeitet werden müssen, bietet RAG klare Vorteile.
Was ist eine Vektor-Datenbank im Zusammenhang mit RAG?
Eine Vektor-Datenbank speichert Dokumente als mathematische Embeddings. Bei einer Anfrage wird die Nutzerfrage ebenfalls in einen Vektor umgewandelt und semantisch mit gespeicherten Dokumenten verglichen. So findet RAG relevante Inhalte für die Antwortgenerierung.
Reduziert RAG Halluzinationen?
Ja, Retrieval-Augmented Generation reduziert Halluzinationen, da das Large Language Model auf konkrete Dokumente zugreift. Die Antwort basiert somit stärker auf realem Kontext statt nur auf statistischen Wahrscheinlichkeiten.
Ist RAG eine eigene KI oder nur eine Technik?
RAG ist keine eigenständige KI, sondern eine Architektur, die ein Large Language Model mit einem Retrieval-System kombiniert. Es handelt sich um eine Erweiterung bestehender Sprachmodelle, nicht um ein neues Modelltyp.
Kann RAG mit Echtzeit-Daten arbeiten?
Ja, sofern die Datenquelle regelmäßig aktualisiert wird. RAG kann neue Dokumente indexieren, ohne das zugrunde liegende Large Language Model neu zu trainieren. Dadurch eignet sich RAG für dynamische Informationsumgebungen.