Wie funktioniert ein Large Language Model?
Ein Large Language Model analysiert Milliarden Textdaten, erkennt semantische Zusammenhänge mittels Transformer-Architektur und generiert kontextbasierte Sprache.
Diese Technologie bildet das Fundament moderner KI-Systeme – von Chatbots bis hin zu autonomen Agenten.
Large Language Model (LLM)
Architektur, Funktionsweise und Bedeutung moderner KI
Ein Large Language Model (LLM) ist ein auf neuronalen Netzen basierendes KI-Modell, das darauf trainiert wurde, menschliche Sprache zu verstehen, zu verarbeiten und zu generieren. Der Begriff „Large“ bezieht sich dabei nicht nur auf die Datenmenge, sondern vor allem auf die Anzahl der Modellparameter – moderne Large Language Models besitzen Milliarden bis hin zu mehreren Billionen Parametern.
Ein LLM analysiert Sprache nicht semantisch im menschlichen Sinne, sondern statistisch. Es berechnet die Wahrscheinlichkeit, welches Wort – präziser: welcher Token – als nächstes folgt. Aus dieser scheinbar simplen Wahrscheinlichkeitsberechnung entsteht jedoch die Fähigkeit, Texte zu schreiben, Code zu generieren, Fragen zu beantworten, juristische Dokumente zusammenzufassen oder komplexe Zusammenhänge zu erklären.
Large Language Models sind das technologische Fundament moderner generativer KI-Systeme und bilden die Basis von Chatbots, KI-Assistenten, Content-Generatoren und autonomen Agentensystemen.
Historische Entwicklung von Large Language Models
Von regelbasierten Systemen zu neuronalen Netzen
Frühe Sprachmodelle waren regelbasiert oder nutzten statistische N-Gramm-Modelle. Diese Systeme konnten lediglich Wortfolgen anhand lokaler Wahrscheinlichkeiten vorhersagen. Sie hatten kein Verständnis für langfristige Abhängigkeiten im Text.
Mit der Einführung neuronaler Netze begann ein Paradigmenwechsel. Rekurrente neuronale Netze (RNNs) und später LSTM-Modelle konnten erstmals längere Kontextbeziehungen modellieren. Dennoch waren sie ineffizient und schwer parallelisierbar.
Der Durchbruch: Transformer-Architektur
Der entscheidende Durchbruch für Large Language Models war die Einführung der Transformer-Architektur im Jahr 2017. Das zentrale Konzept des Transformers ist der sogenannte Self-Attention-Mechanismus. Dieser erlaubt es dem Modell, jedes Wort im Kontext aller anderen Wörter zu gewichten.
Dadurch entstand erstmals ein System, das:
- Langfristige Abhängigkeiten effizient modellieren kann
- Vollständig parallelisierbar ist
- Massive Skalierung ermöglicht
Ohne Transformer gäbe es keine modernen LLMs.
Architektur eines Large Language Models
Ein Large Language Model basiert in der Regel auf folgenden Kernkomponenten:
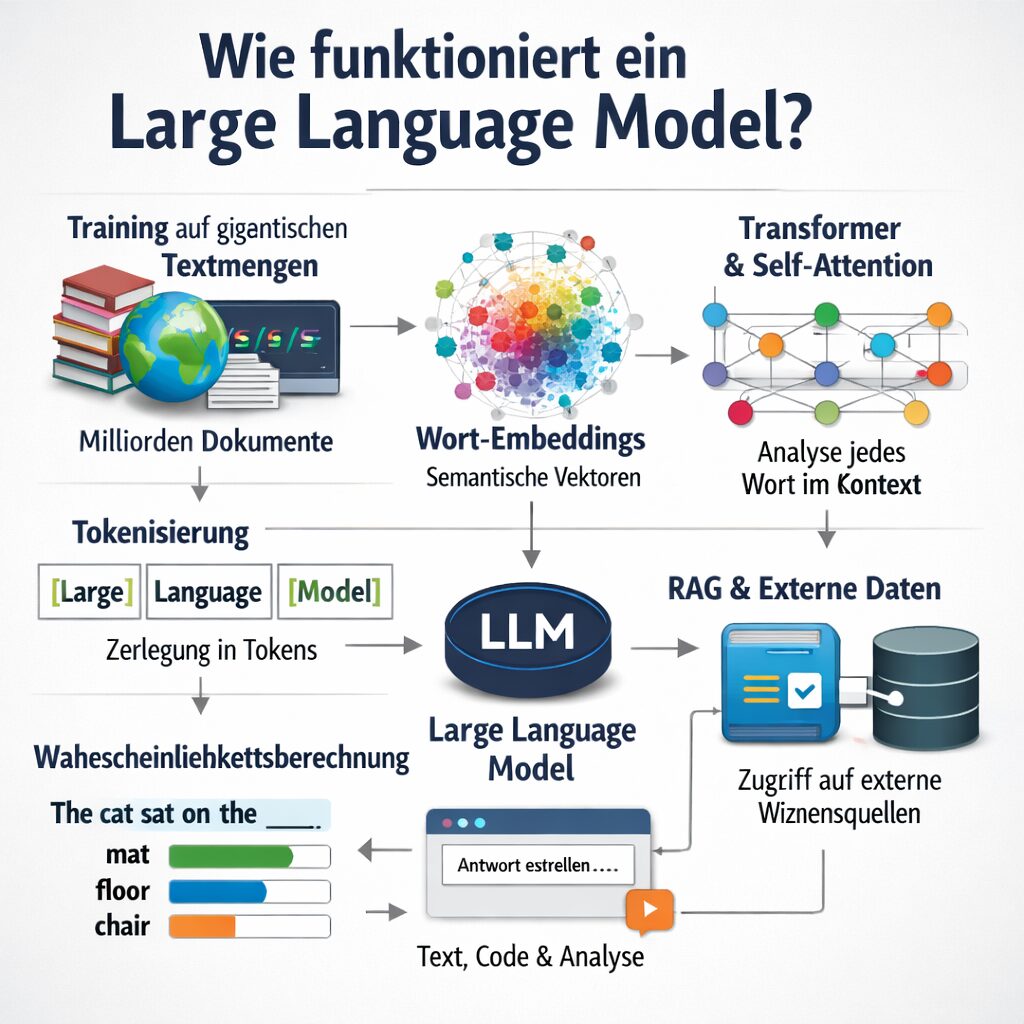
Tokenisierung
Bevor ein Text verarbeitet werden kann, muss er in Tokens zerlegt werden. Ein Token kann ein Wort, ein Wortfragment oder ein Zeichen sein.
Beispiel:
„Large Language Model“ →
[Large] [Language] [Model]
Tokenisierung ist essenziell, da das Modell keine „Wörter“ kennt, sondern numerische Repräsentationen verarbeitet.
Embedding
Jeder Token wird in einen Vektorraum transformiert. Diese Vektoren – sogenannte Embeddings – repräsentieren semantische Beziehungen.
Beispiel:
„König“ – „Mann“ + „Frau“ ≈ „Königin“
Embeddings ermöglichen es dem Large Language Model, semantische Ähnlichkeiten mathematisch abzubilden.
Self-Attention Mechanismus
Der Self-Attention-Mechanismus erlaubt es dem Modell, die Relevanz jedes Tokens im Kontext zu bestimmen.
Beispiel:
Im Satz:
„Der Hund, der im Park spielte, war laut.“
Das Modell erkennt, dass „der“ sich auf „Hund“ bezieht – nicht auf „Park“.
Diese Kontextverarbeitung ist der Kern moderner Large Language Models.
Transformer-Layer
Ein LLM besteht aus vielen gestapelten Transformer-Schichten. Jede Schicht:
- Berechnet Attention
- Wendet Feed-Forward-Netzwerke an
- Normalisiert und transformiert die Daten
Je mehr Layer und Parameter ein Modell besitzt, desto komplexere Sprachmuster kann es erfassen.
Trainingsprozess eines Large Language Models
Pre-Training
Im Pre-Training wird das Large Language Model auf riesigen Textkorpora trainiert. Ziel ist meist:
„Vorhersage des nächsten Tokens.“
Das Modell lernt dabei:
- Grammatik
- Stil
- Weltwissen (indirekt)
- Zusammenhänge
Wichtig:
Das Modell „versteht“ nicht – es lernt statistische Muster.
Fine-Tuning
Nach dem Pre-Training erfolgt häufig ein Fine-Tuning auf spezifische Aufgaben:
- Dialogoptimierung
- Fachgebiete
- Sicherheitsanpassung
- Tonalität
Fine-Tuning macht aus einem generischen Large Language Model ein spezialisiertes System.
Reinforcement Learning from Human Feedback (RLHF)
Moderne LLMs werden zusätzlich mit menschlichem Feedback optimiert. Dadurch lernen sie:
- Hilfreiche Antworten zu bevorzugen
- Problematische Inhalte zu vermeiden
- Dialogstruktur zu verbessern
Warum „Large“ so entscheidend ist
Die Leistungsfähigkeit eines Large Language Models skaliert stark mit:
- Anzahl der Parameter
- Größe des Trainingsdatensatzes
- Rechenleistung
Empirisch zeigt sich eine Skalierungsgesetzmäßigkeit:
Mehr Parameter + mehr Daten → bessere Sprachkompetenz.
Deshalb besitzen moderne LLMs hunderte Milliarden Parameter.
Fähigkeiten von Large Language Models
Ein Large Language Model kann:
- Texte generieren
- Code schreiben
- Sprachen übersetzen
- Zusammenfassungen erstellen
- Dokumente analysieren
- Fragen beantworten
- Logische Schlüsse simulieren
Allerdings basiert alles auf Wahrscheinlichkeitsberechnung – nicht auf Bewusstsein.
Grenzen eines Large Language Models
Halluzinationen
Ein LLM kann falsche Informationen generieren, wenn die statistische Wahrscheinlichkeit plausibel erscheint.
Fehlendes echtes Verständnis
Ein Large Language Model besitzt kein Bewusstsein und kein echtes Weltmodell.
Trainingsdaten-Bias
Modelle spiegeln Verzerrungen aus Trainingsdaten wider.
Large Language Model vs klassische KI-Systeme
| Klassische KI | Large Language Model |
|---|---|
| Regelbasiert | Neuronale Netze |
| Spezialisiert | Generalistisch |
| Begrenzte Skalierung | Massive Skalierung |
| Kein generativer Output | Generative KI |
LLMs sind flexible Universalmodelle für Sprache.
Retrieval-Augmented Generation (RAG) und LLM
Ein reines Large Language Model basiert nur auf Trainingsdaten.
Mit RAG wird das Modell mit externem Wissen kombiniert.
Ablauf:
- Suchsystem durchsucht Datenbank
- Relevante Dokumente werden eingefügt
- LLM generiert Antwort basierend auf Kontext
Dadurch entsteht eine deutlich höhere Faktengenauigkeit.
Wirtschaftliche Bedeutung von Large Language Models
Large Language Models verändern:
- Content-Produktion
- Softwareentwicklung
- Kundenservice
- Finanzanalyse
- Bildung
- Medizin
Sie sind Infrastruktur-Technologie, vergleichbar mit Cloud-Computing.
Einsatzgebiete von Large Language Models
Finanzen
- Marktanalyse
- Sentiment-Analyse
- Trading-Strategien
- News-Zusammenfassungen
Unternehmen
- Automatisierung von Support
- Dokumentenanalyse
- Wissensmanagement
Entwickler
- Code-Generierung
- API-Dokumentation
- Debugging-Unterstützung
Sicherheitsaspekte von Large Language Models
- Prompt Injection
- Datenleaks
- Modell-Missbrauch
- Desinformation
Unternehmen müssen Governance-Strukturen aufbauen.
Zukunft von Large Language Models
Die Entwicklung geht in Richtung:
- Multimodale Modelle
- Agentensysteme
- On-Device LLMs
- Effizientere Architektur
- Spezialisierte Branchen-LLMs
LLMs werden zunehmend mit Datenbanken, APIs und Automatisierungsplattformen kombiniert.
Technische Schlüsselbegriffe im Zusammenhang mit LLM
Kontextfenster
Maximale Anzahl an Tokens, die verarbeitet werden können.
Parameter
Gewichte im neuronalen Netz, die trainiert werden.
Inferenz
Der Prozess der Antwortgenerierung.
Prompt Engineering
Optimierung der Eingabe, um bessere Ergebnisse zu erzielen.
Fazit: Warum Large Language Models die Grundlage moderner KI sind
Ein Large Language Model ist kein simples Sprachprogramm. Es ist eine hochskalierte neuronale Architektur, die statistische Sprachmuster in einer bisher unerreichten Tiefe modelliert.
LLMs sind:
- Infrastruktur-Technologie
- Innovationsbeschleuniger
- Automatisierungswerkzeug
- Produktivitätsmultiplikator
Gleichzeitig bleiben sie probabilistische Systeme mit klaren Grenzen.
Für dein KI-Portal bildet dieses Thema das Fundament für alle weiteren Deep-Dive-Seiten wie:
- RAG
- Vektor-Datenbanken
- Fine-Tuning
- Prompt Engineering
- KI-Agenten
FAQ zu Large Language Model
Was ist ein Large Language Model einfach erklärt?
Ein Large Language Model (LLM) ist ein KI-System, das mithilfe neuronaler Netze große Mengen an Text analysiert und daraus Sprache generiert. Es berechnet statistisch das wahrscheinlich nächste Wort im Kontext und kann dadurch Texte schreiben, Fragen beantworten oder Code erstellen. Moderne LLMs basieren auf der Transformer-Architektur.
Wie funktioniert ein Large Language Model?
Ein Large Language Model zerlegt Text in Tokens, wandelt diese in numerische Vektoren um und verarbeitet sie durch mehrere Transformer-Schichten. Mithilfe des Self-Attention-Mechanismus erkennt das Modell Zusammenhänge im Kontext und berechnet die wahrscheinlichste Fortsetzung eines Satzes.
Warum heißt es „Large“ Language Model?
„Large“ bezieht sich auf die enorme Anzahl an Parametern und Trainingsdaten. Moderne LLMs besitzen Milliarden bis Billionen Parameter. Je größer das Modell und die Trainingsdatenmenge, desto besser kann es Sprachmuster erfassen und komplexe Aufgaben lösen.
Was ist der Unterschied zwischen LLM und klassischer KI?
Klassische KI-Systeme sind meist regelbasiert oder auf spezifische Aufgaben spezialisiert. Ein Large Language Model hingegen ist ein generalistisches neuronales Netz, das auf riesigen Textmengen trainiert wurde und vielfältige Sprachaufgaben flexibel lösen kann.
Was ist der Unterschied zwischen LLM und Chatbot?
Ein Large Language Model ist das zugrunde liegende KI-Modell. Ein Chatbot ist eine Anwendung, die ein LLM nutzt, um dialogfähig zu sein. Das LLM erzeugt die Antworten, während der Chatbot die Benutzeroberfläche bereitstellt.
Können Large Language Models denken?
Nein. Ein Large Language Model besitzt kein Bewusstsein und kein echtes Verständnis. Es berechnet statistische Wahrscheinlichkeiten für Wortfolgen. Der Eindruck von „Denken“ entsteht durch komplexe Mustererkennung, nicht durch kognitive Prozesse.
Was sind Halluzinationen bei LLMs?
Halluzinationen entstehen, wenn ein Large Language Model plausible, aber faktisch falsche Informationen generiert. Dies passiert, weil das Modell Wahrscheinlichkeiten berechnet und keine externe Faktenprüfung durchführt.
Wofür werden Large Language Models eingesetzt?
Ein Large Language Model arbeitet nur mit seinem trainierten Wissen. Retrieval-Augmented Generation (RAG) kombiniert ein LLM mit einer externen Datenquelle, um aktuelle oder spezifische Informationen in die Antwort einzubeziehen.
Sind Large Language Models sicher?
LLMs können Sicherheitsrisiken bergen, etwa durch Datenleaks oder Prompt-Injection. Unternehmen müssen Governance-Regeln, Zugriffskontrollen und Monitoring implementieren, um Risiken zu minimieren.